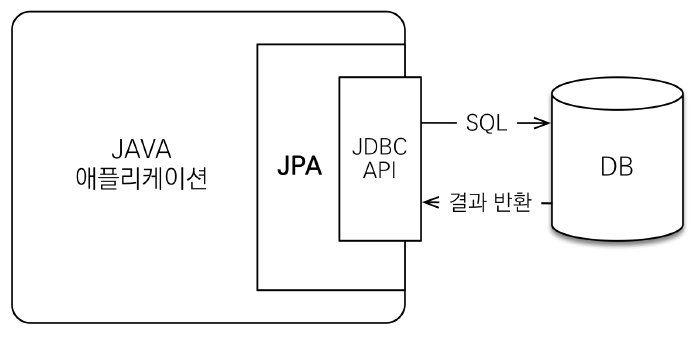
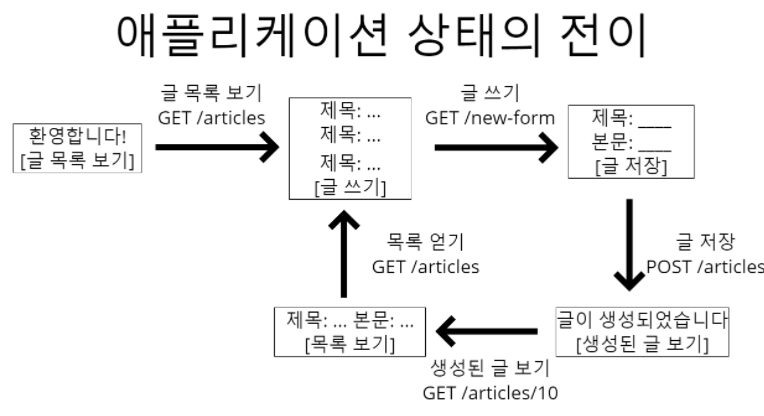
사실 자료구조 카테고리에 맞는 게시글이지만 아직 자료구조 카테고리가 없고 앞으로 딱히 만들 계획이 없기에, 그리고 구현을 자바로 했기에 자바 카테고리에 넣었다! 그냥 그런걸로 하자 ㅎㅎ
해시란?
해쉬브라운
해시란 임의의 크기를 가진 데이터를 고정된 크기의 데이터로 변화시켜 저장하는것이다. 이 과정은 해시함수를 통해 진행되며 해시값 자체를 index로 사용하기에 평균 시간복잡도가 O(1)으로 매우 빠르다
키(key) 1개와 값(value) 1개가 1:1로 연관되어 있는 자료구조이다. 따라서 키(key)를 이용하여 값(value)을 도출할 수 있다.
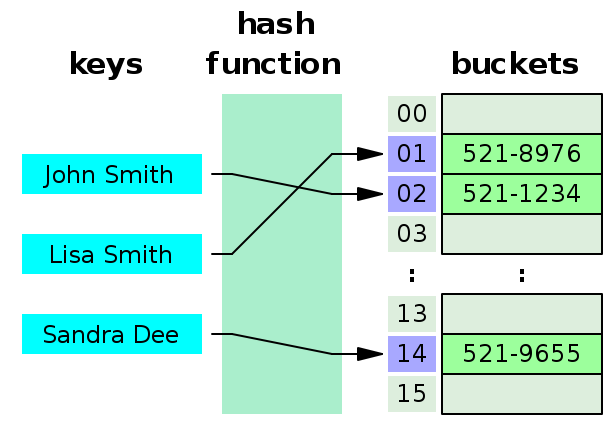
이 그럼처럼 John Smith라는 이름과 전화번호가 매핑이 되어있고 전화번호를 찾기위해선 John Smith라는 이름을 해시함수를 통해 변환한 해시코드를 통해 찾을 수 있다.
해시함수와 충돌
key를 해시함수를 통해서 해시코드로 변환시키고 이 해시코드를 인덱스로 사용하여 value를 저장하는데, 이때 충돌(Collision)이 발생할 수 있다. 다음의 예시를 보자
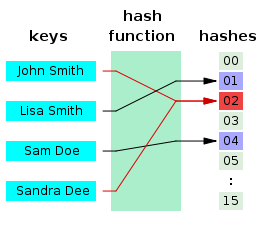
John Smith와 Sandra Dee라는 key가 해시함수를 통해 해시코드로 변환되었는데 우연히 같은 코드로 변환된 것이다.
즉, 무한한 값(KEY)을 유한한 값(HashCode)으로 표현하면서
서로 다른 두 개 이상의 유한한 값이 동일한 출력 값을 가지게 된다는 것이다.
key가 될 수 있는 경우는 무한하고 해시테이블은 유한하니 소위 비둘기집 원리라고 부르는 문제가 발생한다. 이런 문제로 인해 우리는 해시함수의 중요성을 느낄 수 있다. 최대한 겹치지 않고 다양한 값을 보장하는 해시 함수라면 이런 문제를 조금 개선할 수 있지만 그래도 근본적으로는 불가능하다. 따라서 우리는 다른 개선방법을 사용한다. 크게 두가지의 해결 방법이 있는데 Separate Chaining기법과 Open Addressing(개방 주소법)이 있다.
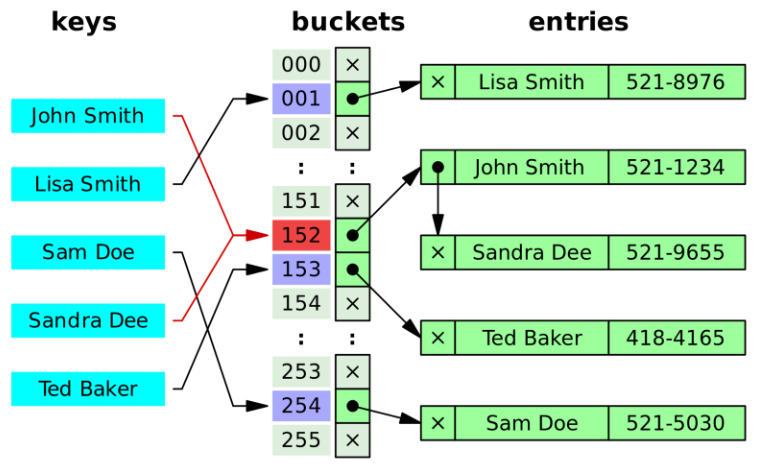
충돌 해결1. Separate Chaining(Chaining) 기법
John Smith가 들어가 있는데 그 공간에 또 Sandra Dee가 들어갈때 Collision이 발생한다. 이때 Sandra의 value를 기존 John의 뒤에 체인처럼 이어 붙혀준다. 152번지에 John과 Sandra의 정보가 함께 존재하도록 한것이다.
장점
한정된 저장 공간을 효율적으로 사용할 수 있다.
해시 함수에 대한 의존성이 상대적으로 적다.
메모리 공간을 미리 잡아 놓을 필요가 없다.(그때그때 이어 붙이기 때문)
단점
한 hash에만 자료가 계속 들어간다면(쏠린다면) 검색 효율이 떨어진다(.최악의 경우 O(n))
외부 저장공간을 사용한다.
충돌 해결2. Open Addressing(개방주소법)
개방주소법은 데이터의 해시(hash)가 변경되지 않았던 chaining과는 달리 비어있는 해시(hash)를 찾아 데이터를 저장하는 기법이다. 따라서 개방주소법에서의 해시테이블은 1개의 해시와 1개의 값(value)가 매칭되어 있는 형태로 유지된다.
장점
추가 저장공간이 필요없다
단점
해시 함수의 성능에 전체 해시테이블의 성능이 좌지우지 된다.
데이터의 길이가 늘어나면 그에 해당하는 저장소를 마련해 두어야한다.
Chaining 기법을 사용한 해시테이블 구현
HashTable 클래스
import java.util.LinkedList;
public class HashTable {
class Node{
String key;
String value;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
String getValue() {
return value;
}
void setValue(String value) {
this.value = value;
}
}
//각 배열 칸에 링크드리스트를 넣음으로서 collision이 발생할 시 뒤에 이어나간다.
LinkedList<Node>[] data;
//해시테이블을 생성하는 순간 생성자를 통해서 배열 크기 초기화
HashTable(int size){
this.data = new LinkedList[size];
}
//키를 해쉬코드로 변환하는 메소드
int getHashCode(String key) {
int hashcode = 0;
for(char c : key.toCharArray()) {
hashcode += c;
}
return hashcode;
}
//해쉬코드를 배열의 인덱스로 변환하는 메소드
int convertHashCodeToIndex(int hashcode) {
return hashcode % data.length;
}
//배열의 인덱스에 노드가 여러개 있다면 key를 통해 알맞은 value를 찾는 메소드
Node searchKey(LinkedList<Node> list , String key) {
//리스트에 아무것도 없으면 null 반환
if(list == null) {
return null;
}
//리스트에 있는 노드중에 찾는 key를 가진 노드가 있다면 반환
for(Node node : list) {
if(node.key.equals(key)) {
return node;
}
}
//리스트에 노드가 없다면 null 반환
return null;
}
//key-value를 저장하는 메소드
void put(String key, String value) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
//배열의 해당 인덱스에 들어가있던 리스트 가져온다
LinkedList<Node> list = data[index];
//배열의 해당 인덱스 번지에 아직 리스트가 없다면
if(list == null) {
//리스트 만들고 해당 인덱스에 넣는다
list = new LinkedList<Node>();
data[index] = list;
}
//가져온 리스트에 지금 넣고자하는 key가 먼저 들어가있는지 확인
Node node = searchKey(list, key);
//노드가 없다면 처음 들어가는 key라는 의미
if(node == null) {
list.addLast(new Node(key, value));
}
else {
//이미 해당 key로 들어가있는 노드가 있다면 지금 넣는 key로 덮어쓰기
node.value = value;
}
}
//key를 통해 value 가져오는 메소드
String get(String key) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
LinkedList<Node> list = data[index];
//해당 인덱스에 있는 list에서 key를 통해 value를 찾는다
Node node = searchKey(list, key);
//해당 key값의 node가 없으면 Not Found반환, 있으면 value 반환
return node == null ? "Not Found" : node.value;
}
}
HashTest 클래스
public class HashTest {
public static void main(String[] args) {
//크기 3의 해쉬테이블 생성
HashTable ht = new HashTable(3);
ht.put("Lee", "lee is pretty");
ht.put("Kim", "kim is smart");
ht.put("Hee", "hee is an angel");
ht.put("Choi", "choi is cute");
//존재하는 데이터 검색
System.out.println(ht.get("Lee"));
System.out.println(ht.get("Kim"));
System.out.println(ht.get("Hee"));
System.out.println(ht.get("Choi"));
//존재하지 않는 데이터 검색
System.out.println(ht.get("Kang"));
//기존 데이터 덮어쓰기
ht.put("Choi", "choi is sexy");
System.out.println(ht.get("Choi"));
}
}
데이터는 Node라는 클래스 형태로 저장된다. Node는 key와 value를 가지고 있고 Value의 getter와 setter가 있다.
해시테이블은 배열로 선언하였고 각 칸마다 LinkedList<Node>형으로 선언하여 chaining 기법을 통한 Collision 회피 기법을 선택하였다.
//각 배열 칸에 링크드리스트를 넣음으로서 collision이 발생할 시 뒤에 이어나간다.
LinkedList<Node>[] data;
해시함수는 key의 각 문자들을 유니코드로 반환하여 모두 더하는 방식으로 구성했다.
인덱스는 해시코드를 해시테이블의 사이즈로 나눈 나머지 값을 사용했다.
//키를 해쉬코드로 변환하는 메소드
int getHashCode(String key) {
int hashcode = 0;
for(char c : key.toCharArray()) {
hashcode += c;
}
return hashcode;
}
//해쉬코드를 배열의 인덱스로 변환하는 메소드
int convertHashCodeToIndex(int hashcode) {
return hashcode % data.length;
}
조회를 희망하는 key를 받아서 value를 찾는 메소드이다. key를 받아서 해시함수로 변환 후 인덱스로 변환하여 해당 인덱스에 존재하는 list를 가져온다. 그 리스트에서 우리가 입력한 key를 가진 Node를 찾는 searchKey 메소드를 통해 목적 Node를 찾아낸다.
//key를 통해 value 가져오는 메소드
String get(String key) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
LinkedList<Node> list = data[index];
//해당 인덱스에 있는 list에서 key를 통해 value를 찾는다
Node node = searchKey(list, key);
//해당 key값의 node가 없으면 Not Found반환, 있으면 value 반환
return node == null ? "Not Found" : node.value;
}
searchKey 메소드에서는 우리가 입력한 key를 가진 Node가 존재하는지 확인한다.
//배열의 인덱스에 노드가 여러개 있다면 key를 통해 알맞은 value를 찾는 메소드
Node searchKey(LinkedList<Node> list , String key) {
//리스트에 아무것도 없으면 null 반환
if(list == null) {
return null;
}
//리스트에 있는 노드중에 찾는 key를 가진 노드가 있다면 반환
for(Node node : list) {
if(node.key.equals(key)) {
return node;
}
}
//리스트에 노드가 없다면 null 반환
return null;
}
해시테이블에 데이터를 넣는 메소드로 chaining 기법을 구현했다. 중복되는 key가 이미 존재할 경우 해당 key에대한 value를 덮어쓰는 것으로 구현했다.
//key-value를 저장하는 메소드
void put(String key, String value) {
int hashcode = getHashCode(key);
int index = convertHashCodeToIndex(hashcode);
//배열의 해당 인덱스에 들어가있던 리스트 가져온다
LinkedList<Node> list = data[index];
//배열의 해당 인덱스 번지에 아직 리스트가 없다면
if(list == null) {
//리스트 만들고 해당 인덱스에 넣는다
list = new LinkedList<Node>();
data[index] = list;
}
//가져온 리스트에 지금 넣고자하는 key가 먼저 들어가있는지 확인
Node node = searchKey(list, key);
//노드가 없다면 처음 들어가는 key라는 의미
if(node == null) {
list.addLast(new Node(key, value));
}
else {
//이미 해당 key로 들어가있는 노드가 있다면 지금 넣는 key로 덮어쓰기
node.value = value;
}
}
class Person<T>{
public T info;
}
public class GenericDemo {
public static void main(String[] args) {
Person<String> p1 = new Person<String>();
Person<Integer> p2 = new Person<Integer>();
}
}
Person 클래스를 생성할때 <여기>에 타입을 지정해주면 제네릭 변수 T를 통해서 info의 타입이 정해진다. T라는 문자 말고 다른 문자를 써도 되지만 암묵적인 룰이 있다.
타입
설명
<T>
Type
<E>
Element
<K>
Key
<V>
Value
<N>
Number
그러면 이걸 왜 쓰는 것이고 쓰면 뭐가 좋은지 예제를 통해 탐구해보자.
제네릭을 쓰면 좋은점
타입안정성을 확보하고 중복을 줄일 수 있다.
먼저 다음의 중복이 있는 코드를 보자
class StudentInfo{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class StudentPerson{
public StudentInfo info;
StudentPerson(StudentInfo info){ this.info = info; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class EmployeePerson{
public EmployeeInfo info;
EmployeePerson(EmployeeInfo info){ this.info = info; }
}
public class WithoutGeneric {
public static void main(String[] args) {
StudentInfo si = new StudentInfo(2);
StudentPerson sp = new StudentPerson(si);
System.out.println(sp.info.grade); // 2
EmployeeInfo ei = new EmployeeInfo(1);
EmployeePerson ep = new EmployeePerson(ei);
System.out.println(ep.info.rank); // 1
}
}
타입안정성이 확보된 코드이지만, StudentPerson 클래스와 EmployeePerson에서 중복이 발생했다. 같은 목적의 클래스이지만 타입이 다르기에 두번 쓴것인데 이를 개선하고자 이 두 클래스를 Person이라는 하나의 클래스로 통일해보자.
class StudentInfo{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person{
public Object info;
Person(Object info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person("부장");
EmployeeInfo ei = (EmployeeInfo)p1.info;
System.out.println(ei.rank);
}
}
모든 타입을 받을 수 있는 Object형으로 info를 선언함으로 중복을 줄였다.
그리고 EmployeeInfo ei = (EmployeeInfo)p1.info 으로 EmployeeInfo의 객체를 생성하려고 했다. 이때 컴파일에서 잡히지 않던 에러가 발생한다. 바로 EmployeeInfo의 멤버변수 rank는 int형인데 여기에 "부장"이라는 String을 넣으려고 한다는 에러다. 이번에는 중복을 줄였지만 타입안정성을 확보하지 못한 모습을 볼 수 있다.
이제 제네릭을 적용해서 중복과 타입 안정성을 모두 챙겨보자.
class StudentInfo{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T>{
public T info;
Person(T info){ this.info = info; }
}
public class WithGeneric {
public static void main(String[] args) {
Person<EmployeeInfo> p1 = new Person<EmployeeInfo>(new EmployeeInfo(1));
EmployeeInfo ei1 = p1.info;
System.out.println(ei1.rank); // 성공
Person<String> p2 = new Person<String>("부장");
String ei2 = p2.info;
System.out.println(ei2.rank); // 컴파일 실패
}
}
이 경우에는 맨 마지막줄에서 빨간줄이 뜨면서 컴파일 에러가 발생한다. 즉 중요한것은
런타임이 아닌 컴파일 단계에서 오류가 검출된다.
중복의 제거와 타입 안정성을 동시에 추구할 수 있다.
제네릭의 특성
1. 복수의 제네릭도 가능하다
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
}
2. 기본타입은 안되고 참조타입만 사용할 수 있다.
제네릭의 제한
제네릭으로 올 수 있는 데이터 타입을 특정 클래스의 자식으로 제한할 수 있다.
abstract class Info{
public abstract int getLevel();
}
class EmployeeInfo extends Info{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
public int getLevel(){
return this.rank;
}
}
class Person<T extends Info>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person(new EmployeeInfo(1));
Person<String> p2 = new Person<String>("부장");
}
}
class Person<T extends Info>를 보면 T타입은 Info클래스 자신이거나 이것을 상속받는 타입만 가능하다는 의미이다. 상속뿐 아니라 인터페이스의 implements도 가능하다. 반대로 부모타입만 가능하다는 의미의 super도 가능하다!
이번 포스팅은 네이버 D2 유튜브에 올라온 "그런 REST API로 괜찮은가" 영상을 토대로 작성하였다.
REST(REpresentational State Transfer) API란
REST API는 REST 아키텍처를 따르는 API이다. 문장을 하나씩 뜯어보자
REST → 분산 하이퍼미디어 시스템(ex. 웹)을 위한 아키텍처 스타일
아키텍처 스타일 → 제약 조건의 집합
API → API는 응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
즉, REST에서 정의한 제약 조건을 모두 지켜야 REST를 따른다고 말할 수 있다는 것이다.
REST의 장단점
장점
1. Easy to use
REST API의 가장 큰 장점이라고 할 수 있다. 단순히REST API 메시지를 읽는 것 만으로도 메시지가 의도하는 바를 명확하게 파악할 수 있다. 굳이 해당 메시지의 기능이 무엇인지 알기 위해 메뉴얼을 하나씩 읽어 볼 필요가 없게 만들어 준다.
HTTP 인프라를 그대로 사용하기 때문에, REST API 사용을 위한 별도의 인프라 구축을 요구하지 않는다. 그리고 Stateless한 특징 때문에 수행 문맥(Execution Context)가 독립적으로 진행됨으로써 이전에 서버(호스트)에서 진행된 내용들에 대해 클라이언트가 알 필요가 없으며, 이제까지 진행된 히스토리에 대해서도 알 필요가 없게 된다. 즉해당 URI와 원하는 메소드 자체만 독립적으로 이해하면 된다.
2. Complete Seperation between Client and Server
클라이언트는 REST API를 이용하여 서버와 정보를 주고 받는다. 위에서 언급한 Stateless 한 특징에 따라, 서버는 클라이언트의 문맥을 유지할 필요가 없게 된다. 결국 클라이언트와 서버는 서로 신경쓰지 않으며 동작하게 된다. 서로에게 무관심한 이기적인 상황인 것이다. 하지만 실제로는각자의 역할이 명확하게 분리되어 있다는 의미로 보는게 더 맞다.
이러한 장점으로 인해 플랫폼의 독립성 확장이라는 효과를 가져오고 HTTP 프로토콜만 지켜진다면 다양한 플랫폼에서 원하는 서비스를 쉽고 빠르게 개발/배포할 수 있게 된다.
3. Detail expression for specific data type
REST API는 헤더 부분에 URI 처리 메소드를 명시함으로써, 필요한 실제 데이터를 페이로드(바디)에 표현할 수 있도록 구성할 수 있는 기능을 제공한다. 이는특정 메소드의 세부적인 표현 문구를 JSON, XML 등 다양한 언어를 이용하여 작성할 수 있다는 장점 뿐만 아니라, 간결한 헤더 표현을 통한 가독성 향상이라는 두마리 토끼를 잡는 효과를 가져다 주게 된다.
단점
1. Restriction of HTTP MethodREST
API는 HTTP 메소드를 사용하여 URI를 표현한다. 이러한 표현 방법은 다양한 인프라에서도 편리하게 사용할 수 있다는 장점을 주지만, 또 한편으로는 메소드 형태가 제한적이라는 문제점을 가져오기도 한다.
2. Absence of Standard (표준의 부재)
REST API의 가장 큰 단점이라고 할 수 있는데, 바로 표준이 존재하지 않는다는 것이다.
이는관리의 어려움과 좋은(공식화 된) API 디자인 가이드가 존재하지 않음을 의미하는데, 결국 REST API는 많은 사람들이 하나씩 쌓아올리는 ‘정당화 된 약속들’ 로 구성되고 움직이게 된다.
REST를 구성하는 스타일
Client-Server
Stateless
Cache
Uniform Interface
Layered System
Code-on-Demand (optional)
대체로 REST라고 부르는 것들은 위의 조건을 대부분 지키고 있다. 왜냐하면 HTTP만 잘 따라도 Client-Server, Stateless, Cache, Layered System은 다 지킬 수 있기 때문이다. Code-on-Demand는 서버에서 코드를 클라이언트로 보내서 실행할 수 있어야 한다는 것을 의미, 즉 자바스크립트를 의미한다. 이는 필수는 아니다.
단, 4번의 Uniform Interface는 잘 지켜지지 않는다고 한다.
Uniform Interface 제약 조건
Identification of resources
Manipulation of resources through representations
Self-descriptive messages
Hypermedia as the engine of application state(HATEOAS)
Identification of resources은URI로 리소스가 식별되면 된다는 것이고, Manipulation of resources through representations는representation 전송을 통해서 리소스를 조작해야된댜는 것이다. 즉, 리소스를 만들거나 삭제, 수정할 때 http 메시지에 그 표현을 전송해야된다는 것이다. 위 2가지 조건은 대부분 잘 지켜지고 있다. 하지만 문제는 아래 2개이다. 이 2가지는 사실 우리가 REST API라고 부르는 거의 모든 것들은 지키지 못하고 있다.
Uniform Interface의 세번째, 네번째 조건에 대해 알아보자
세번째 조건. Self-descriptive messages
Self-descriptive message라는 것은 메시지를 봤을 때 메시지의 내용으로 온전히 해석이 다 가능해야된다는 것이다.
예를 들어 아래와 같은 메시지가 있다고 해보자
GET / HTTP/1.1
단순히 루트를 얻어오는 GET 요청이다. 이 HTTP 요청 메시지는 목적지가 빠져있어서 Self-descriptive하지 못하다. 다음과 같이 수정할 수 있겠다.
클라이언트가 GET 메소드로 URI 주소 '/member/1'를 호출한다면 사용자 ID가 1인 '사용자 정보'를 갖고온다고 가정해보자. 이때 동일한 URI로 DELETE 메소드를 호출 할 경우 사용자 삭제가 가능하고, PUT 메소드를 호출할 경우 업데이트라고 한다면 일일히 클라이언트 쪽에 알려줘야 한다는 번거로움이 발생한다. 이것을 줄이고자 호출한 URI로부터 연관된 REST API 주소 정보들을 함께 보내주는 역할을 하는 것이 HATEOAS 이다. 그럼으로써 클라이언트는 서버와 상호 작용하는 방법에 대한 사전 지식이 거의 또는 전혀 필요없이 사용 할 수 있게 되는 것이다.
HTTP(Hypertext Transfer Protocol)는 인터넷상에서 데이터를 주고 받기 위해 서버/클라이언트 모델을 따르는 통신규약이다. 이 HTTP 프로토콜에는 비연결성(Connectionless)과 비상태성(Stateless)이라는 특징이 있다.
Connectionless 프로토콜 (비연결지향)
클라이언트가 서버에 요청(Request)을 했을 때, 그 요청에 맞는 응답(Response)을 보낸 후 연결을 끊는 처리방식이다.
HTTP 1.1 버전에서 연결을 유지하고, 재활용 하는 기능이 Default 로 추가되었다. (keep-alive 값으로 변경 가능)
Stateless 프로토콜 (상태정보 유지 안함)
클라이언트와 첫번째 통신에서 데이터를 주고 받았다 해도, 두번째 통신에서 이전 데이터를 유지하지 않는다.
클라이언트의 상태 정보를 가지지 않는 서버 처리 방식이다.
하지만 이로 인해 사용자를 식별할 수 없어서 같은 사용자가 요청을 여러번 하더라도 매번 새로운 사용자로 인식하는 단점이 있다. 이를 해결하기 위해 세션과 쿠키를 사용한다.
즉, 클라이언트와정보 유지를 하기 위해 사용하는 것이 쿠키와 세션이다.
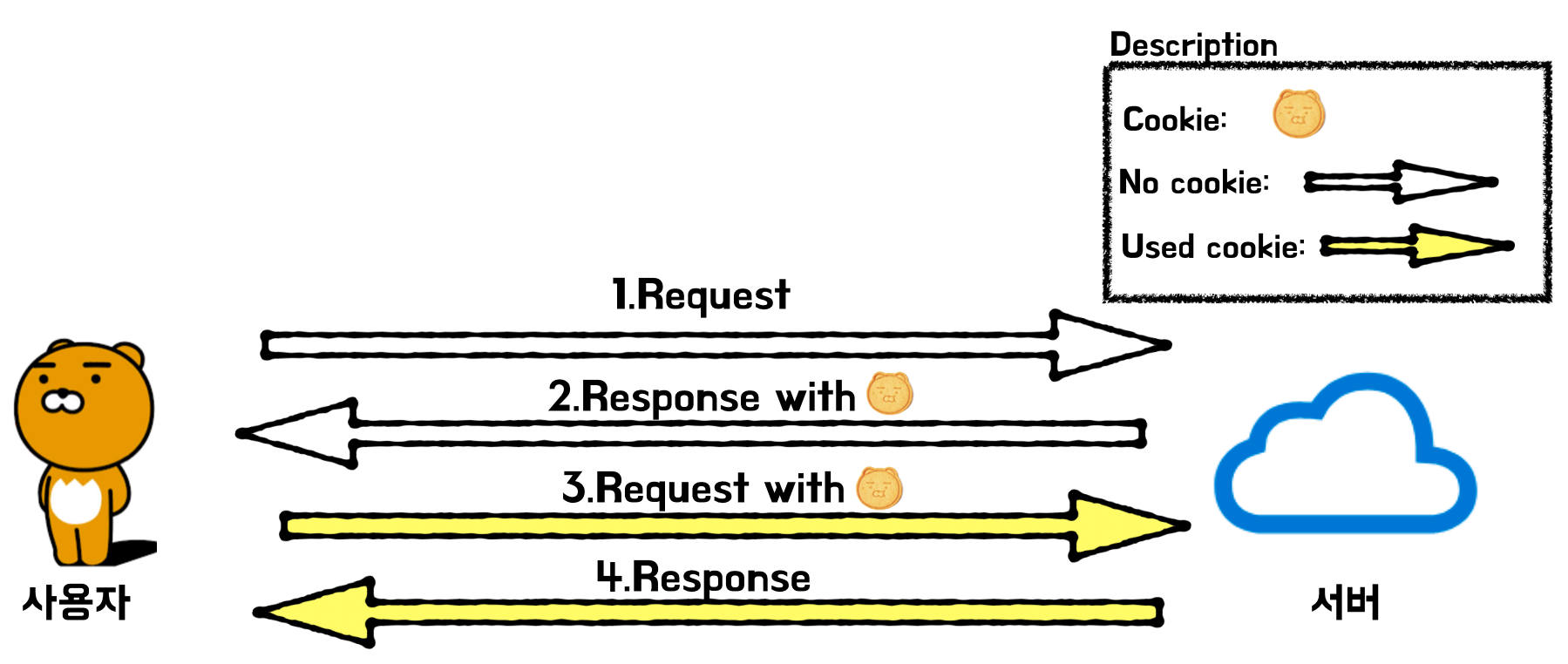
쿠키(Cookie)
HTTP의 일종으로 사용자가 어떠한 웹 사이트를 방문할 경우, 그 사이트가 사용하고 있는 서버에서사용자의 컴퓨터에 저장하는 작은 기록 정보 파일이다.
HTTP에서 클라이언트의 상태 정보를 클라이언트의 PC에 저장하였다가 필요시 정보를 참조하거나 재사용할 수 있다.
쿠키의 발급/사용 절차
쿠키 특징
이름, 값, 만료일(저장 기간 설정), 경로 정보로 구성되어 있다.
클라이언트에 총 300개의 쿠키를 저장할 수 있다.
하나의 도메인 당 20개의 쿠키를 가질 수 있다
하나의 쿠키는 4KB까지 저장 가능하다.
쿠키의 동작 순서
브라우저에서 웹페이지에 접속한다.
클라이언트가 요청한 웹페이지를 응답으로 받으면서 HTTP 헤더를 통해 해당 서버에서 제공하는 쿠키 값을 응답으로 준다. (이러면 클라이언트는 해당 쿠키를 저장한다.)
클라이언트가 웹페이지를 요청한 서버에 재 요청시 받았던 쿠키 정보도 같이 HTTP 헤더에 담아서 요청한다.
서버는 클라이언트의 요청(Request)에서 쿠키 값을 참고하여 비즈니스 로직을 수행한다. (ex 로그인 상태 유지)
즉, HTTP요청시 서버로부터 쿠키를 발급받고 이후 요청들에 쿠키를 함께 동봉하여 요청한다.
사용 예시
방문했던 사이트에 다시 방문 하였을 때 아이디와 비밀번호 자동 입력
팝업창을 통해 "오늘 이 창을 다시 보지 않기" 체크
쿠키는 사용자가 별도로 요청하지 않아도 브라우저(Client)에서 서버에 요청(Request) 시에 Request Header에 쿠키 값을 넣어 요청한다. (=자동이다.)
그렇다고 그 많은 쿠키 값을 굳이 모든 요청에 넣어서비효율적으로 동작하지는 않는다.도메인 설정을 통해서 지정한 도메인으로 요청할 때만 쿠키 값이 제공되도록 할 수도 있다.
세션(Session)
서버(Server)에 클라이언트의 상태 정보를 저장하는 기술로논리적인 연결을 세션이라고 한다.
웹 서버에 클라이언트에 대한 정보를 저장하고 클라이언트에게는 클라이언트를 구분할 수 있는 ID를 부여하는데 이것을 세션아이디라 한다.
세션 특징
세션은 쿠키를 기반하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리한다.
서버에서는 클라이언트를 구분하기 위해 SessionID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지한다.
물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 정보가 유지되지 않게 설정이 가능하다.
사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 된다.
즉 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 된다.
클라이언트가 Request를 보내면, 해당 서버의 엔진이 클라이언트에게 유일한 ID를 부여하는 데 이것이 SessionID다.
세션의 동작 순서
클라이언트가 서버에 접속 시 Session ID를 발급받는다.
클라이언트는 SessionID에 대해 쿠키를 사용해서 저장하고 가지고 있다.
클라리언트는 서버에 요청할 때, 이 쿠키의 SessionID를 서버에 전달해서 사용한다.
서버는 SessionID를 전달 받아서 별다른 작업없이 SessionID로 Session에 있는 클라이언트 정보를 가져온다.
클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답한다.
즉. 클라이언트가 가진 쿠키에 존재하는 세션ID와 서버가 가진 세션ID를 비교하여 식별.
사용 예시
방문했던 사이트에 다시 방문 하였을 때 아이디와 비밀번호 자동 입력
팝업창을 통해 "오늘 이 창을 다시 보지 않기" 체크
세션과 쿠키 활용
쿠키와 세션의 차이
저장 위치
쿠키는 클라이언트(브라우저)에 메모리 또는 파일에 저장하고, 세션은 서버 메모리에 저장된다.
보안
쿠키는 클라이언트 로컬(local)에 저장되기도 하고 특히 파일로 저장되는 경우 탈취, 변조될 위험이 있고, Request/Response에서 스나이핑 당할 위험이 있어 보안이 비교적 취약하다. 반대로 Session은 클라이언트 정보 자체는 서버에 저장되어 있으므로 비교적 안전하다.
라이프 사이클
쿠키는 앞서 설명한 지속 쿠키의 경우에 브라우저를 종료하더라도 저장되어 있을 수 있는 반면에 세션은 서버에서 만료시간/날짜를 정해서 지워버릴 수 있기도 하고 세션 쿠키에 세션 아이디를 정한 경우, 브라우저 종료시 세션아이디가 날아갈 수 있다.
속도
쿠키에 정보가 있기 때문에 쿠키에 정보가 있기 때문에 서버에 요청시 헤더를 바로 참조하면 되므로 속도에서 유리하지만, 세션은 제공받은 세션아이디(Key)를 이용해서 서버에서 다시 데이터를 참조해야하므로 속도가 비교적 느릴 수 있다.
세션을 주로 사용하면 좋은데 왜 굳이 쿠키를 사용할까?
→ 세션은 서버에 데이터를 저장 즉, 서버의 자원을 사용하기 때문에 서버 자원에 한계가 있고 메모리를 사용하다보면 속도 저하도 올 수 있기 때문이다.
세션은 사용자의 수 만큼 서버 메모리를 차지하기 때문에 최근에는 이런 문제들을 보완한 토큰 기반의 인증방식을 사용하는 추세다. 그 중 JWT( JSON Web Token)라는 것이 있다. JWT는 다음에 포스팅해보도록 하겠다.
프로그래밍을 하다보면 사용하지 않는 일명 "쓰레기"공간이 발생하여 프로그램의 성능을 저하시킨다. 자바에선 가비지 컬렉터가 이를 자동으로 탐지하여 해결해주는데 이 일을 해주는 가비지 컬렉터에 대해 알아보자. (이하 GC라고 하겠다.)
GC란
Person p1 = new Person("Kim");
Person p2 = new Person("Lee");
// p2가 가리키던 객체는 가비지가 된다.
p2 = p1;
Kim이라는 이름을 가진 p1 객체와 Lee라는 이름을 가진 p2객체가 있는데 p2라는 참조변수가 p1객체를 가리키게 한다면 원래 p2가 가리키던 Lee라는 객체는 더 이상 참조받을 수 없다. 즉 unreachable object가 되며 이를 가비지라고 한다.
가비지 컬렉션이란
JVM의 힙영역에서 사용하지 않는 객체를 삭제하는 프로세스를 말한다.
GC는 Mark and sweep 알고리즘을 통해 동작한다.
mark는 reachable한 객체와 unreachable한 객체를 식별하는 과정
sweep은 식별한 unreachable객체를 제거하는 과정
compact과정도 추가되기도 한다. (메모리 단편화를 방지)
언제 동작하는가
GC도 결국엔 JVM에 올라가기 때문에 기본적으로 런타임에 동작한다.
가비지 컬렉션이 실행되기에는 몇 가지 조건이 있는데, 다음 조건 중 하나라도 충족되면 JVM은 GC를 실행한다.
OS로부터 할당 받은 시스템의 메모리가 부족한 경우
관리하고 있는 힙에서 사용되는 메모리가 허용된 임계값을 초과하는 경우
프로그래머가 직접 GC를 실행하는 경우(Java에서는 System.gc()라는 메소드가 있지만 가급적 안 쓰는 것이 좋다.)
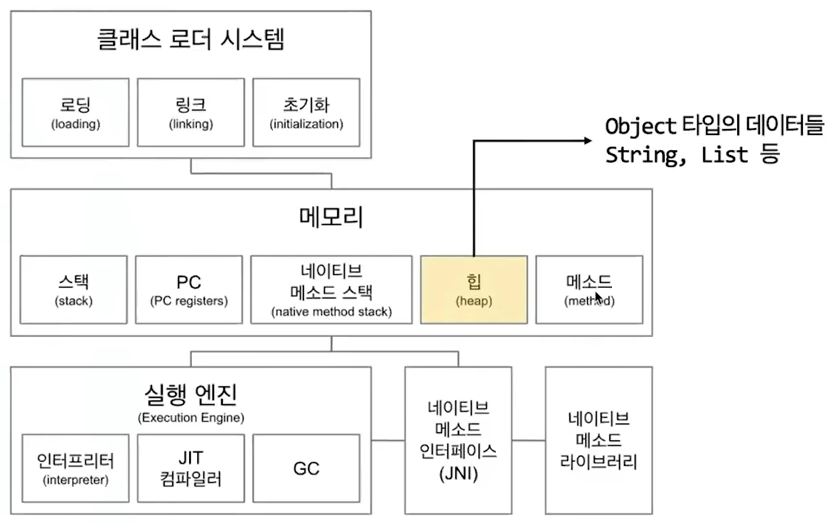
JVM의 Heap 메모리 구조
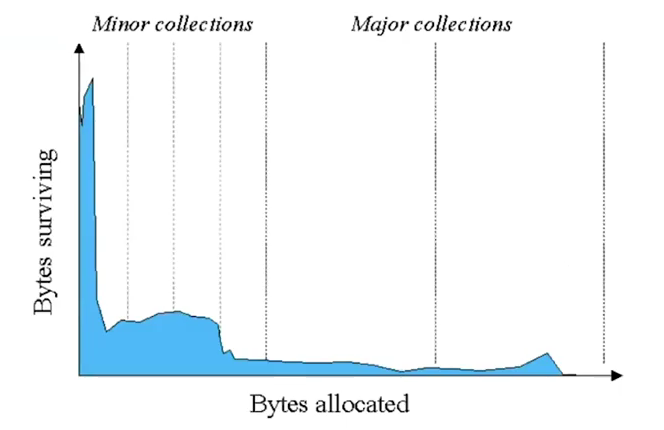
이렇게 생겼다. 여기서 우리는 오른쪽의 Permanent영역을 제외한 부분만 살펴보자. 참고로 Young 영역에서 발생하는 GC를 Minor GC, Old영역의 GC는 Major GC라고 한다. Minor GC와 Major GC를 따로 만든 이유는 대부분의 객체는 금방 가비지가 된다는 가설을 전제로 하고 GC를 설계했기 때문이다.
Minor GC의 범위에서 사용되는 객체들(파란영역)이 훨씬 많은것을 알 수 있다.
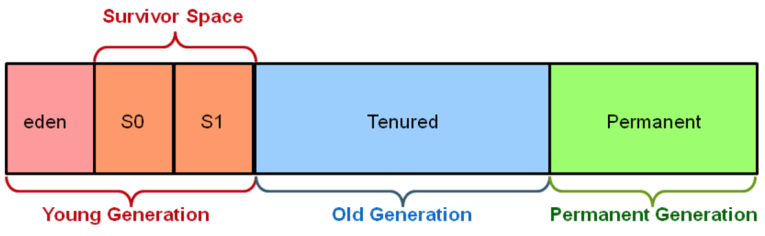
Young Generation
GC를 이해하기 위해서 객체가 제일 먼저 생성되는 Young 영역부터 알아보자. Young 영역은 3개의 영역으로 나뉜다.
Eden 영역
Survivor 영역(2개)
Survivor 영역이 2개이기 때문에 총 3개의 영역으로 나뉘는 것이다. 각 영역의 처리 절차를 순서에 따라서 기술하면 다음과 같다.
새로 생성한 대부분의 객체는 Eden 영역에 위치한다.
Eden영역이 꽉 차면 GC(Minor GC)가 발생한다.
Eden 영역에서 GC(Minor GC)가 한 번 발생한 후 살아남은 객체는 Survivor 영역 중 하나로 이동된다.
이때 Survivor영역은 둘 중 한쪽만 사용돼야 한다.
그렇기에 Minor GC가 발생할때 마다 두 군데의 Survivor 영역을 이동하며 저장된다.
GC가 발생할때마다 살아남은 객체들은 Age가 증가한다.
일정 Age에 도달한 객체들은 Old 영역으로 이동하게 된다.
이 절차를 확인해 보면 알겠지만 Survivor 영역 중 하나는 반드시 비어 있는 상태로 남아 있어야 한다. 만약 두 Survivor 영역에 모두 데이터가 존재하거나, 두 영역 모두 사용량이 0이라면 여러분의 시스템은 정상적인 상황이 아니라고 생각하면 된다.
Old Generation
Young 영역에서 오랫동안 살아남은 객체들이 넘어오는 곳이다. 이곳 역시 꽉차면 Major GC의 과정이 수행된다. 주로 5가지의 GC방식이 존재한다.
스레드는 작업의 한 단위이다. 프로세스는 독자적인 메모리를 할당받아서 서로 다른 프로세스끼리는 일반적으로 서로의 메모리 영역을 침범하지 못한다. 하지만 프로세스 내부에 있는 여러 스레드들은 서로 같은 프로세스 내부에 존재하고 있기 때문에 같은 자원을 공유하여 사용할 수 있다. 같은 자원을 공유할 수 있기 때문에 동시에 여러 가지 일을 같은 자원을 두고 수행할 수 있고, 이는 곧 병렬성의 향상으로 이어진다.
잠깐 동시성과 병렬성을 짚고 넘어가자
동시성 VS 병렬성
동시성
병렬성
동시에 실행되는 것 같이 보이는 것
실제로 동시에 여러 작업이 처리되는 것
싱글 코어에서 멀티 쓰레드(Multi thread)를 동작 시키는 방식
멀티 코어에서 멀티 쓰레드(Multi thread)를 동작시키는 방식
한번에 많은 것을 처리
한번에 많은 일을 처리
논리적인 개념
물리적인 개념
첫번째 그림은 그냥 순차적으로 실행되는 모습(싱글코어)
두번째 그림은 동시성으로 실행되는 모습. 실제로 작업의 흐름은 한가닥이지만 여러 작업을 번갈아가며 조금씩 수행하기에 마치 동시에 진행되는 것 처럼 보인다. 작업 전환시마다 컨텍스트 스위칭이라고 비용이 발생한다.(싱글코어)
세번째 그림은 병렬성 작업으로 실제로 동시에 따로 작업이 진행되는 것이다.(멀티코어)
쓰레드 안정이 깨지는 상황
멀티 스레드 환경에서 스레드 안전(Thread-safe)한 프로그램을 제작하기 위해서는 어떤 경우에 스레드 안전하지 않은 동작이 생기는지 먼저 만들어볼 필요가 있다. 정말 간단한 예제로, 조회수 계산 로직이 있다. 특정 글을 조회하는 순산 원래 조회수에 1을 더한 값을 저장할 것이고, 여러 사용자가 동시에 접근할 것이므로 멀티 스레드 환경에서 동작한다고 가정해 보겠다.
public class CountingTest {
public static void main(String[] args) {
Count count = new Count();
for (int i = 0; i < 100; i++) {
new Thread(){
public void run(){
for (int j = 0; j < 100; j++) {
System.out.println(count.view());
}
}
}.start();
}
}
}
class Count {
private int count;
public int view() {return count++;}
public int getCount() {return count;}
}
해당 코드를 실행시켰을 때, 100명의 사용자가 100번 조회했으므로100 * 100, 즉 10000번의 조회수가 나올것이라 예상 할 수 있다.
하지만 실제 결과값을 보았을 때는 10000번이 아닌 그보다 더 적은 조회수가 나온다. 그 이유는 조회수를 증가시키는 로직이 두 번의 동작으로 이루어지는데 동시에 여러 스레드가 접근하여 첫 번째 동작할 때의 자원과 두 번째 동작할 때의 자원 상태가 변하기 때문이다.
count++는
1. count변수 값을 조회한다.
2. count변수에 조회한 값에 1을 더한 값을 저장한다.
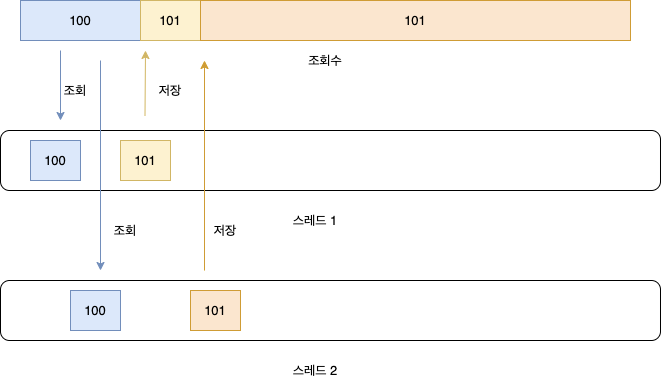
를 수행한다. 이때 발생하는 문제가 여러 쓰레드에서 count 변수를 동시에 조회하면 발생한다.
그림처럼 쓰레드1과 2에서 동시에 count변수의 값을 조회하면 둘 다 100이라는 값에 1을 더한 값을 count변수에 다시 저장하기에 102가 나와야하지만 실제론 101이 되는 것이다.
동시성을 제어하는 방법
1. 암시적 Lock
하나의 쓰레드가 접근했을때 다른 쓰레드는 접근하지 못하도록 Lock을 거는것이다. 동시성 문제를 해결할 수 있지만 한번에 하나의 쓰레드만 접근이 가능하므로 병렬성은 매우 떨어진다. 메서드에 synchronized 키워드를 붙이면 암시적 락을 적용할 수 있다.
메서드 Lock
class Count {
private int count;
public synchronized int view() {return count++;}
}
변수 Lock
class Count {
private Integer count = 0;
public int view() {
synchronized (this.count) {
return count++;
}
}
}
2. 명시적 Lock
synchronized 키워드 없이 명시적으로 ReentrantLock을 사용하는 Lock을 명시적 Lock이라고한다. 해당 Lock의 범위를 메서드 내부에서 한정하기 어렵거나, 동시에 여러 Lock을 사용하고 싶을 때 사용한다.
명시적 Lock을 사용한 예제
public class CountingTest {
public static void main(String[] args) {
Count count = new Count();
for (int i = 0; i < 100; i++) {
new Thread(){
public void run(){
for (int j = 0; j < 1000; j++) {
count.getLock().lock();
System.out.println(count.view());
count.getLock().unlock();
}
}
}.start();
}
}
}
class Count {
private int count = 0;
private Lock lock = new ReentrantLock();
public int view() {
return count++;
}
public Lock getLock(){
return lock;
};
}
3. 자원의 가시성을 책임지는 volatile
여러 쓰레드가 하나의 자원에 동시에 읽기/쓰기를 진행할때 항상 메모리에 접근하지 않는다. 성능 향상을 위해 CPU 캐시를 참조하여 값을 조회하는데 이 값과 메인 메모리의 값이 항상 일치하는지 보장할 수 없다. 즉, 변수를 조회하여 값을 읽었는데 실제 값과 다를 수 있다는 말이다. 실제 자원의 값(메인 메모리 값)을 볼 수 있는 개념을 자원의 가시성이라고 부르는에 이 자원의 가시성을 확보하지 못한것이다.
"멀티쓰레드 환경에서 쓰레드가 변수를 읽어올 때,
CPU 캐시에 저장된 값이 다르기 때문에 변수 값 불일치 문제가 발생"
public class SharedObject {
public int counter = 0;
}
Thread-1은 counter값을 증가시키고 있지만 CPU Cache에만 반영되어있고 실제로 Main Memory에는 반영이 되지 않는 상태. 그렇기 때문에 Thread-2는 count값을 계속 읽어오지만 0을 가져오는 문제가 발생.
volatile은 이러한 CPU 캐시 사용을 막는다. 해당 변수에 volatile 키워드를 붙여주면 해당 변수는 캐시에 저장되는 대상에서 제외된다. 매 번 메모리에 접근해서 실제 값을 읽어오도록 설정해서 캐시 사용으로 인한데이터 불일치를 막는다. 실제 메모리에 저장된 값을 조회하고 이를 통해 자원의 가시성을 확보할 수 있다.
public class SharedObject {
public volatile int counter = 0;
}
volatile은 자원의 가시성을 확보해주지만 동시성 이슈를 해결하기에는 그리 충분하지 않다. 공유 자원에 read&write를 할 때는 동기화를 통해 해당 연산이 원자성을 이루도록 설정해주어야 동시성 이슈를 해결할 수 있다.
volatile이 효과적인 경우는 하나의 스레드가 wtite를 하고 다른 하나의 스레드가 read만 할 경우다. 이 경우 read만 하는 스레드는 CPU 캐시를 사용하고 다른 스레드가 write한 값을 즉각적으로 확인하지 못한다. volatile은 이런 경우 해당 자원에 가시성을 확보하게 해 줌으로써 동시성 이슈 해결에 도움을 줄 수 있다.
4. 쓰레드 안전한 객체 사용
Concurrunt 패키지를 통해 쓰레드 안전한 구조를 챙길 수 있다.
class Count {
private AtomicInteger count = new AtomicInteger(0);
public int view() {
return count.getAndIncrement();
}
}
5. 불변 객체
String 객체처럼한번 만들면 그 상태가 변하지 않는 객체를 불변객체라고 한다. 불변 객체는 락을 걸 필요가 없다. 내부적인 상태가 변하지 않으니 여러 스레드에서 동시에 참조해도 동시성 이슈가 발생하지 않는다는 장점이 있다. 즉, 불변 객체는 언제라도 스레드 안전.
불변 객체는 객체의 상태를 변화시킬 수 있는 부분을 모두 제거해야한다. setter를 만들지 말고 final로 선언하면 된다.