클레이튼 기반의 dapp을 개발하며 블록체인의 트랜잭션과 서비스의 데이터베이스간의 싱크를 보장해야하는 상황을 마주했다.
성공한 트랜잭션이면 관련 정보를 데이터베이스에 반영해주고,
실패한 트랜잭션이면 관련 정보를 데이터베이스에 반영해주지 않는, 그런 요구사항이었다.
클레이튼 블록체인에서 자체적으로 실패한 트랜잭션에 대한 롤백은 시켜주기에 클레이튼의 성공여부를 먼저 확인하고 데이터베이스 반영 여부를 정해야했다. [클레이튼 트랜잭션] -> [데이터베이스 트랜잭션]의 플로우였기에 이 사이에 트랜잭션의 성공여부만 확인하고 데이터베이스의 트랜잭션을 발생시킬지 말지 결정하면 됐다.
[클레이튼 트랜잭션] -> [트랜잭션이 성공했는지 확인] -> [데이터베이스 트랜잭션]
하지만 블록체인은 트랜잭션이 확정되기까지 걸리는 시간인 Finality라는 개념이 있기에 트랜잭션의 성공 여부를 조회하려면 이 Finality 시간 이후에 해야했다. 클레이튼의 경우 이 시간이 평균 1초라고 알려져있다. 평균이기에 실제 상황에서 약간의 오차는 있을 것 이다. 따라서 Finality만큼의 딜레이를 하고 트랜잭션 조회 -> 데이터베이스 트랜잭션 실행의 절차를 밟아야 했다.
즉, 필요한 조건은
1. 트랜잭션 조회에 delay를 줘야한다. -> Finality 때문에
2. 적어도 2회 이상 retry를 하며 조회해야한다. -> Finality 시간이 일정하지 않기 때문에
3. 최대한 빠르게 트랜잭션의 성공 여부를 판단해야한다. -> 원활한 서비스 제공을 위해
2. 고려했던 선택지
세가지를 고려했었다. 참고로 NodeJS로 개발했다.
1. 스케줄러를 통해 짧은 간격으로 확정되지 않은 트랜잭션들의 성공 여부를 조회하기
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다.
NodeJS의 스케줄러를 통해서 is_confirmed가 false인 기록들을 짧은 간격으로 주기적으로 조회하며 트랜잭션의 성공 여부를 확인한다.(트랜잭션 성공여부는 caverExtKAS 라이브러리의 getTransferHistoryByTxHash 함수를 사용했다)
문제점.
트랜잭션이 발생하지 않을때도 몇 초마다 항상 실행되기에 리소스 낭비라고 생각됐다.
2. 클레이튼 이벤트 리스너를 통해 트랜잭션이 수행될 때 발생되는 이벤트를 추적하여 판별하기
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다.
트랜잭션이 성공하면 열어둔 소켓을 통해 클레이튼 이벤트를 Listen할 수 있는데 트랜잭션이 성공하면 이벤트가 수신되므로(아마..?) 수신했다는 것은 해당 트랜잭션이 성공했다는 의미.
문제점.
가끔 성공한 트랜잭션의 이벤트가 리슨되지 않을때가 있었다. (왜일까..)
3. RabbitMQ를 통해서 딜레이와 재시도 기능을 구현하여 조회하기 (이 방법을 사용했다)
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다. 또 동시에 RabbitMQ로 발생한 트랜잭션의 정보를 publish한다.
컨슈머에서 이를 구독하고 이 시점에 트랜잭션 성공 여부를 조회한다.
트랜잭션이 성공이면 데이터베이스에도 관련 정보를 반영 후 ack으로 마무리하고, 실패면 retry_count를 1추가해서 DLX로 보낸다. 이곳에서 5000ms동안 대기하고 다시 작업큐로 메시지를 보내서 반복한다.(넉넉히 5초로 딜레이를 주었다)
3번에서 반복 횟수동안 모두 트랜잭션이 확정이 안됐거나 실패 판정이 나면 데이터베이스에 관련 정보를 반영하지 않고 ack을 반환한다.
이 방법을 선택한 이유
RabbitMQ를 통해서 사용자가 몰릴때 비동기적으로 안정적인 로직 수행이 가능하기에
RabbitMQ의 Durability를 통해 중요한 정보를 잃어버리지 않을 수 있기에
RabbitMQ의 DLX 기능을 통해 딜레이와 재시도를 구현할 수 있기에
3. RabbitMQ 구성
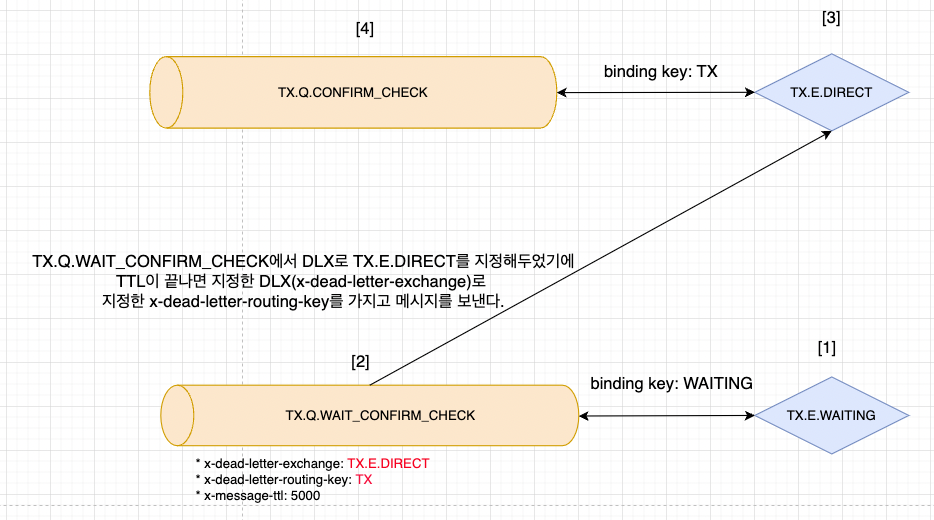
RabbitMQ는 위와같이 구성해보았다.
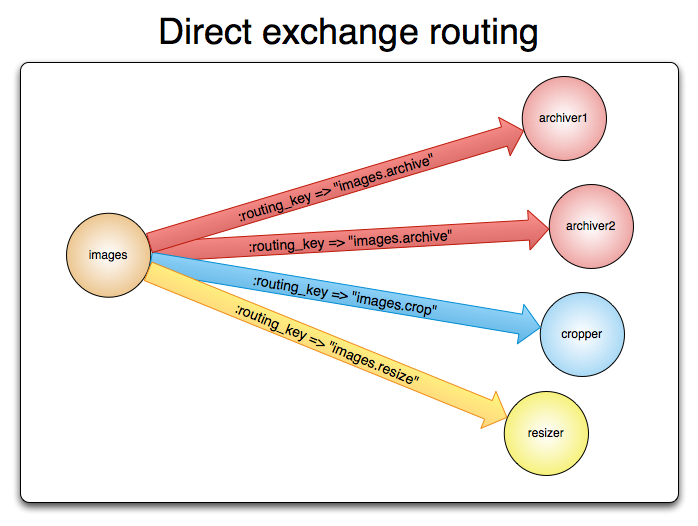
[1], [2]
클레이튼 트랜잭션을 발생시킴과 동시에 트랜잭션의 정보와 retry_count를 담은 메시지를 publish한다.
[3], [4]
지정한 익스체인지에서 지정한 큐로 메시지를 전달한다.
[5]
트랜잭션의 성공 여부를 확인하는 컨슈머에서 트랜잭션의 성공 여부를 확인한다.
성공이라면 서비스 로직을 실행하고 ack을 반환한다.
[6]
트랜잭션이 아직 확정되지 않았거나 실패했다면 WAITING 익스체인지로 같은 메시지를 그대로 전달한다.
이때마다 retry_count에 1 씩 더해서 전달한다.
[7]
전달된 메시지는 TX.Q.WAIT_CONFIRM_CHECK 큐로 보내지는데 이 큐는 DLX와 TTL 설정이 돼있다.
[8]
지정한 TTL 시간이 지나면 메시지가 x-dead-letter-exchange로 지정된 익스체인지로 x-dead-letter-routing-key 바인딩 키를 사용해서 전달된다.
즉, 이 큐에서 5000ms 동안 대기하고 TX.E.DIRECT 익스체인지로 가게된다.
이때 바인딩키는 TX를 가지고간다.
TX는 TX.E.DIRECT와 TX.Q.CONFIRM_CHECK의 바인딩키다.
따라서 TX.E.DIRECT 익스체인지에 도착한 메시지는 TX.Q.CONFIRM_CHECK 큐로 다시 보내진다.
[4], [5], [6], [7], [8]의 과정을 최대 3번까지 반복하고도 트랜잭션이 실패라고 판별되면 최종적으로 실패처리(데이터베이스에 반영하지 않기)를 한 후 ack를 반환한다.
RabbitMQ는 데이터를 잠시 보관하고 나중에 비동기적으로 처리하고 싶을 경우 사용하는 일종의 데이터 저장소이다.
*AMQP:Advanced Message Queing Protocol의 약자로, 흔히 알고 있는 MQ의 오픈소스에 기반한 표준 프로토콜
실생활에서 예를 들어보자
스타벅스에서 손님들이 줄을 서서 커피를 주문한다.
1. 메시지 큐X
첫번째 손님이 커피를 주문하면 첫번째 손님의 커피가 완성될때까지 두번째 손님은 계속 줄을 서서 대기해야한다.
2. 메시지 큐O
첫번째 손님은 커피를 주문하고 자리로 간다. 두번째, 세번째 손님들도 주문서만 던져놓고 자리로 간다. 바리스타는 쌓여가는 주문서들을 보며 순서대로 커피를 만든다. 커피가 만들어지면 손님들이 받아간다.
이때 손님(프로듀서)들이 바리스타(컨슈머)에게 던져놓는 주문서가 메시지가 되고 주문서가 쌓여가는 곳이 메시지 큐가 된다.
이런 구조는 커피를 비동기적으로 만들기에 효율적이며,
주문서는 바리스타에게 전달될때 까지 잠시 저장되기에 바리스타가 까먹거나 하는 주문 누락이 발생하지 않는다.
정리하자면
메시지를 많은 사용자에게 전달해야할 때
요청에 대한 처리시간이 길어 해당 요청을 다른 API에 위임하고 빠른 응답처리가 필요할 때
애플리케이션 간 결합도를 낮춰야 할 때
RabbitMQ를 사용한다
2. RabbitMQ는 어떻게 이루어져있는가?
[프로듀서 → 브로커(익스체인지+큐) → 컨슈머]
의 구조로 메시지를 전달해주는 메시징 서버
RabbitMQ는 다음과 같이 구성된다.
Producer: 메시지를 보내는 놈
Exchange: 메시지를 알맞은 큐에 전달해주는 놈
Queue: 메시지를 차곡차곡 쌓아두는 놈
Consumer: 메시지를 받는 놈
위 그럼처럼 Producer는 Queue에 직접 메시지를 전달하는 것이 아니다.
[프로듀서 → 익스체인지 → 큐 → 컨슈머]의 절차를 밟는다.
Exchange에서 알맞은 Queue로 메시지를 분배한다.(Exchange들과 Queue들은 바인딩되어있다)
무슨 기준으로 분배하느냐?
Exchange Type에 따라 다르다.
Exchange Type 4가지
Direct
메시지에 포함된 Routing Key를 기반으로 특정 Queue에 메시지를 하나씩 전달한다.
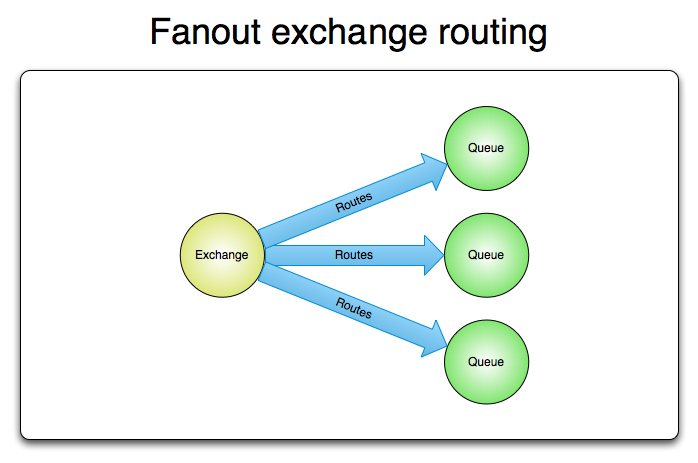
Fanout
Routing Key에 상관 없이 연결돼있는 모든 Queue에 동일한 메시지를 전달한다.
라우팅키를 평가할 필요가 없기때문에 성능적인 이점이 있다.
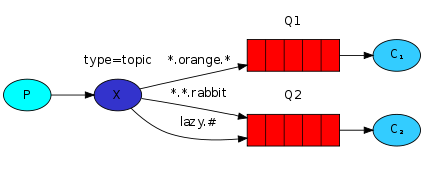
Topic
라우팅키 전체가 일치하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달된다.
Topic Exchange 에서 사용하는 binding key 는 점(.)으로 구분된 단어를 조합해서 정의한다.
* 와 #을 이용해 와일드 카드를 표현할 수 있으며, * 는 단어 하나 일치 # 는 0 또는 1개 이상의 단어 일치를 의미한다.
다음과 같이 binding key 를 정의한 경우에 메시지의 routing key 가 quick.orange.rabbit 또는 lazy.orange.elephant 이면, Q1, Q2 둘 다 전달된다. lazy.pink.rabbit 는 binding key 2개와 일치 하더라도 1번만 전달된다.
quick.brown.fox, quick.orange.male.rabbit 는 일치하는 binding key 가 없기 때문에 무시된다.
Header
메시지 속성 중 headers 테이블을 사용해 특정한 규칙의 라우팅을 처리한다.
x-match = any 일 경우 헤더 테이블 값 중 하나가 연결된 값 중 하나와 일치하면 메시지 전달
앞선 내용들을 통해 각각의 정의 및 프로세스에 대해 면밀히(?) 살펴봤다. 위 내용을 통해서도 kafka와 RabbitMQ의 차이에 대해 어느정도 이해할 수 있겠지만 본 글의 주제가 주제인만큼 다시 한번 간단히 정리해보도록 하겠다.
kafka는 pub/sub 방식 / RabbitMQ는 메시지 브로커 방식 kafka의 pub/sub방식은 생산자 중심적인 설계로 구성. 생성자가 원하는 각 메시지를 게시할 수 있도록 하는 메시지 배포 패턴으로 진행 RabbitMQ의메시지브로커방식은 브로커 중심적인 설계로 구성. 지정된 수신인에게 메시지를 확인, 라우팅, 저장 및 배달하는 역할을 수행하며 보장되는 메시지 전달에 초점
전달된 메시지에 대한 휘발성 RabbitMQ는 queue에 저장되어 있던 메시지에 대해 Event Consumer가져가게 되면 queue에서 해당 메시지를 삭제한다. 하지만, kafka는 생성자로부터 메시지가 들어오면 해당 메시지를 topic으로 분류하고 이를 event streamer에 저장한다. 그 후, 수신인이 특정 topic에 대한 메시지를 가져가더라도 event streamer는 해당 topic을 계속 유지하기 때문에 특정 상황이 발생하더라도 재생이 가능하다.
용도의 차이 kafka는 클러스터를 통해 병렬처리가 주요 차별점인 만큼 방대한 양의 데이터를 처리할 때, 장점이 부각된다. RabbitMQ는 데이터 처리보단 Manage UI를 제공하는 만큼 관리적인 측면이나, 다양한 기능 구현을 위한 서비스를 구축할 때, 장점이 부각된다.
{
"compilerOptions": {
/* Visit https://aka.ms/tsconfig.json to read more about this file */
/* Projects */
// "incremental": true, /* Enable incremental compilation */
// "composite": true, /* Enable constraints that allow a TypeScript project to be used with project references. */
// "tsBuildInfoFile": "./", /* Specify the folder for .tsbuildinfo incremental compilation files. */
// "disableSourceOfProjectReferenceRedirect": true, /* Disable preferring source files instead of declaration files when referencing composite projects */
// "disableSolutionSearching": true, /* Opt a project out of multi-project reference checking when editing. */
// "disableReferencedProjectLoad": true, /* Reduce the number of projects loaded automatically by TypeScript. */
/* Language and Environment */
"target": "es5", /* Set the JavaScript language version for emitted JavaScript and include compatible library declarations. */
// "lib": [], /* Specify a set of bundled library declaration files that describe the target runtime environment. */
// "jsx": "preserve", /* Specify what JSX code is generated. */
// "experimentalDecorators": true, /* Enable experimental support for TC39 stage 2 draft decorators. */
// "emitDecoratorMetadata": true, /* Emit design-type metadata for decorated declarations in source files. */
// "jsxFactory": "", /* Specify the JSX factory function used when targeting React JSX emit, e.g. 'React.createElement' or 'h' */
// "jsxFragmentFactory": "", /* Specify the JSX Fragment reference used for fragments when targeting React JSX emit e.g. 'React.Fragment' or 'Fragment'. */
// "jsxImportSource": "", /* Specify module specifier used to import the JSX factory functions when using `jsx: react-jsx*`.` */
// "reactNamespace": "", /* Specify the object invoked for `createElement`. This only applies when targeting `react` JSX emit. */
// "noLib": true, /* Disable including any library files, including the default lib.d.ts. */
// "useDefineForClassFields": true, /* Emit ECMAScript-standard-compliant class fields. */
/* Modules */
"module": "commonjs", /* Specify what module code is generated. */
// "rootDir": "./", /* Specify the root folder within your source files. */
// "moduleResolution": "node", /* Specify how TypeScript looks up a file from a given module specifier. */
// "baseUrl": "./", /* Specify the base directory to resolve non-relative module names. */
// "paths": {}, /* Specify a set of entries that re-map imports to additional lookup locations. */
// "rootDirs": [], /* Allow multiple folders to be treated as one when resolving modules. */
// "typeRoots": [], /* Specify multiple folders that act like `./node_modules/@types`. */
// "types": [], /* Specify type package names to be included without being referenced in a source file. */
// "allowUmdGlobalAccess": true, /* Allow accessing UMD globals from modules. */
// "resolveJsonModule": true, /* Enable importing .json files */
// "noResolve": true, /* Disallow `import`s, `require`s or `<reference>`s from expanding the number of files TypeScript should add to a project. */
/* JavaScript Support */
// "allowJs": true, /* Allow JavaScript files to be a part of your program. Use the `checkJS` option to get errors from these files. */
// "checkJs": true, /* Enable error reporting in type-checked JavaScript files. */
// "maxNodeModuleJsDepth": 1, /* Specify the maximum folder depth used for checking JavaScript files from `node_modules`. Only applicable with `allowJs`. */
/* Emit */
// "declaration": true, /* Generate .d.ts files from TypeScript and JavaScript files in your project. */
// "declarationMap": true, /* Create sourcemaps for d.ts files. */
// "emitDeclarationOnly": true, /* Only output d.ts files and not JavaScript files. */
"sourceMap": true, /* Create source map files for emitted JavaScript files. */
// "outFile": "./", /* Specify a file that bundles all outputs into one JavaScript file. If `declaration` is true, also designates a file that bundles all .d.ts output. */
"outDir": "dist", /* Specify an output folder for all emitted files. */
// "removeComments": true, /* Disable emitting comments. */
// "noEmit": true, /* Disable emitting files from a compilation. */
// "importHelpers": true, /* Allow importing helper functions from tslib once per project, instead of including them per-file. */
// "importsNotUsedAsValues": "remove", /* Specify emit/checking behavior for imports that are only used for types */
// "downlevelIteration": true, /* Emit more compliant, but verbose and less performant JavaScript for iteration. */
// "sourceRoot": "", /* Specify the root path for debuggers to find the reference source code. */
// "mapRoot": "", /* Specify the location where debugger should locate map files instead of generated locations. */
// "inlineSourceMap": true, /* Include sourcemap files inside the emitted JavaScript. */
// "inlineSources": true, /* Include source code in the sourcemaps inside the emitted JavaScript. */
// "emitBOM": true, /* Emit a UTF-8 Byte Order Mark (BOM) in the beginning of output files. */
// "newLine": "crlf", /* Set the newline character for emitting files. */
// "stripInternal": true, /* Disable emitting declarations that have `@internal` in their JSDoc comments. */
// "noEmitHelpers": true, /* Disable generating custom helper functions like `__extends` in compiled output. */
// "noEmitOnError": true, /* Disable emitting files if any type checking errors are reported. */
// "preserveConstEnums": true, /* Disable erasing `const enum` declarations in generated code. */
// "declarationDir": "./", /* Specify the output directory for generated declaration files. */
/* Interop Constraints */
// "isolatedModules": true, /* Ensure that each file can be safely transpiled without relying on other imports. */
// "allowSyntheticDefaultImports": true, /* Allow 'import x from y' when a module doesn't have a default export. */
"esModuleInterop": true, /* Emit additional JavaScript to ease support for importing CommonJS modules. This enables `allowSyntheticDefaultImports` for type compatibility. */
// "preserveSymlinks": true, /* Disable resolving symlinks to their realpath. This correlates to the same flag in node. */
"forceConsistentCasingInFileNames": true, /* Ensure that casing is correct in imports. */
/* Type Checking */
"strict": true, /* Enable all strict type-checking options. */
// "noImplicitAny": true, /* Enable error reporting for expressions and declarations with an implied `any` type.. */
// "strictNullChecks": true, /* When type checking, take into account `null` and `undefined`. */
// "strictFunctionTypes": true, /* When assigning functions, check to ensure parameters and the return values are subtype-compatible. */
// "strictBindCallApply": true, /* Check that the arguments for `bind`, `call`, and `apply` methods match the original function. */
// "strictPropertyInitialization": true, /* Check for class properties that are declared but not set in the constructor. */
// "noImplicitThis": true, /* Enable error reporting when `this` is given the type `any`. */
// "useUnknownInCatchVariables": true, /* Type catch clause variables as 'unknown' instead of 'any'. */
// "alwaysStrict": true, /* Ensure 'use strict' is always emitted. */
// "noUnusedLocals": true, /* Enable error reporting when a local variables aren't read. */
// "noUnusedParameters": true, /* Raise an error when a function parameter isn't read */
// "exactOptionalPropertyTypes": true, /* Interpret optional property types as written, rather than adding 'undefined'. */
// "noImplicitReturns": true, /* Enable error reporting for codepaths that do not explicitly return in a function. */
// "noFallthroughCasesInSwitch": true, /* Enable error reporting for fallthrough cases in switch statements. */
// "noUncheckedIndexedAccess": true, /* Include 'undefined' in index signature results */
// "noImplicitOverride": true, /* Ensure overriding members in derived classes are marked with an override modifier. */
// "noPropertyAccessFromIndexSignature": true, /* Enforces using indexed accessors for keys declared using an indexed type */
// "allowUnusedLabels": true, /* Disable error reporting for unused labels. */
// "allowUnreachableCode": true, /* Disable error reporting for unreachable code. */
/* Completeness */
// "skipDefaultLibCheck": true, /* Skip type checking .d.ts files that are included with TypeScript. */
"skipLibCheck": true /* Skip type checking all .d.ts files. */
},
"include": [
"src/**/*"
],
"exclude":[
"node_modules"
]
}
이 많은 옵션들 중 내가 사용하고 있는 옵션들부터 살펴보겠다.
compilerOptions과 include/exclude
tsconfig.json 파일을 살펴보면 최상위 경로는 compilerOptions, include, exclude 프로퍼티로 구성돼있다.
compilerOptions은 말 그대로 어떤 컴파일 설정을 사용할지에 대한 속성이다.
include는 프로그램에 포함하고 싶은 파일들의 목록을 지정한다. 보통
{
"include": ["src/**/*", "tests/**/*"]
}
이와 같은 형태로 표기하여 한번에 지정한다.
exclude는 include에 속한 파일들 중에서 제외시킬 파일들을 지정한다. 이때 프로그램에서 포함되지 않도록 제외시키는 메커니즘이 아니라 단순이 include 프로퍼티에서만 제외시킨다는 것에 주의하자.
"target"
여기서부터는 compilerOptions 프로퍼티 내부의 옵션들이다.
target은 어떤 버전의 자바스크립트로 컴파일할지 지정한다.
ts파일들을 tsc로 컴파일하여 js로 만드는 과정이 필요한 타입스크립트이기에 실제 런타임은 대부분 js다. 이 js의 버전을 지정한다.
"module"
프로그램에서 사용할 모듈 시스템을 결정한다. 즉, 모듈 내보내기/불러오기 코드가 어떠한 방식의 코드로 컴파일 될지를 결정한다.
"lib"
타입스크립트 파일을 자바스크립트로 컴파일 할 때 포함될 라이브러리의 목록이다. 이렇게만 하면 와닿지 않는데, async코드를 컴파일 할 때 Promise객체가 필요하므로 "es2017"과 같은 항목을 넣어준다고 한다.
"baseUrl"
비상대적 import의 모듈 해석시 기준이 되는 경로를 지정한다. 예시를 들자면, 프로젝트의 루트 디렉토리에 존재하는 src 디렉토리를 기준으로 각종 모듈들을 불러오고 싶다면 이 프로퍼티를 './src'로 지정한다.
"typeRoots'
기본적으로 @types 패키지들은 컴파일 목록에 포함된다. 하지만 만약 typeRoots 프로퍼티가 특정 경로들로 지정돼 있다면 오직 그 경로에 존재하는 패키지들만 컴파일 목록에 포함된다.
"paths"
baseUrl 기준으로 상대 위치로 가져오기를 다시 매핑하는 항목 설정
"emitDecoratorMetadata"
"experimentalDecorators"
데코레이터 설정이다. 데코레이터란, 자바의 어노테이션과 비슷한 느낌의 기능으로, 데코레이터가 붙은 클래스, 메소드 등에 데코레이터에서 지정한 기능이 동작하도록 하는 기능이다.
"allowSyntheticDefaultImports"
불러오려는 모듈에 default export가 없어도 import * as XXX가 아닌 import XXX로 사용할 수 있게 해주는 설정이다.
"forceConsistentCasingInFileNames"
사용할 파일의 이름을 대소문자까지 정확하게 작성하도록 강제하는 설정이다.
"moduleResolution"
모듈 해석 전략을 결정한다. Nodejs 방식대로 모듈 해석을 하려면 "Node"를, 1.6버전 이전의 타입스크립트에서 사용하던 방식대로 모듈을 해석하려면 "Classic"을 입력한다.
"pretty"
에러와 메시지를 색과 컨텍스트를 사용해서 스타일을 지정하는 옵션
"sourceMap"
빌드시 map파일을 생성할지 설정한다. 생성된 소스맵 파일은 크롬 개발자 도구로 디버깅에 사용된다.
"allowJs"
js파일을 허용하는 옵션이다.타입스크립트는 .js확장자를 허용하지 않는다. 이에대한 예외를 허락하는 옵션.
"esModuleInterop"
"모든 가져오기에 대한 네임스페이스 객체 생성을 통해 CommonJS와 ES 모듈 간의 상호 운용성을 제공"이라고 돼있는데 이게 무슨소리인가?
피부에 와닿진 않지만 Commonjs방식으로 내보낸 모듈을 es모듈 방식의import로 가져올 수 있게 해주는 기능 정도로 일단 이해하자.
csp는 Content-Security-Policy이다. 브라우저에서 사용하는 컨텐츠 기반의 보안 정책으로 XSS나 Data Injection, Click Jacking 등 웹 페이지에 악성 스크립트를 삽입하는 공격기법들을 막기 위해 사용된다.
2. hidePoweredBy
헤더에서 X-Powered-By를 제거한다. 이는 서버에 대한 정보를 제공해주는 역할로 나 같은 경우는 이 영역에 Express라고 표기됨을 확인할 수 있었다. 이 정보는 악의적으로 활용될 가능성이 높기에 헬멧을 통해서 제거해 주는 것이 좋다.
3. HSTS
HTTP Strict Transport Security의 약자로 웹 사이트에 접속할 때 강제적으로 HTTPS로 접속하게 강제하는 기능이다.
사용자가 특정 사이트에 접속할 때 해당 사이트가 HTTPS를 지원하는지, 하지 않는지를 미리 모르는 경우가 대부분이다. 그렇기에 브라우저는 디폴트로 HTTP로 먼저 접속을 시도한다. 이때 HTTPS로 지원되는 사이트였다면 301Redirect나 302 Redirect를 응답하여 HTTPS로 다시 접속하도록 한다.
하지만 이때 해커가 중간자 공격을 하여, 중간에 프록시 서버를 두고
[나] <-> [해커] 사이에서는 HTTP 통신을 하고 [해커] <-> [웹사이트] 사이에선 HTTPS 통신을 한다면,
우리의 개인정보가 HTTP 프로토콜을 통해 해커에게로 전해지는 참사가 일어난다.
이러한 공격을 SSL Stripping이라고 하며 이런 공격을 방지하기 위해 HSTS를 설정한다.
4. IeNoOpen
IE8 이상에 대해 X-Download-Options를 설정한다. 이 옵션은 8 버전 이상의 인터넷 익스플로러에서 다운로드된 것들을 바로 여는 것 대신 저장부터 하는 옵션이다. 사용자는 저장부터 하고 다른 응용프로그램에서 열어야 한다.
5. noCache
클라이언트 측에서 캐싱을 사용하지 않도록 하는 설정이다.
6. noSniff
X-Content-Type-Options 를 설정하여 선언된 콘텐츠 유형으로부터 벗어난 응답에 대한 브라우저의 MIME 스니핑을 방지한다. MIME이란 Multipurpose Internet Mail Extensions의 약자로 클라이언트에게 전송된 문서의 다양성을 알려주기 위한 포맷이다. 브라우저는 리소스를 내려받을 때 MIME 타입을 보고 동작하기에 정확한 설정이 중요하다.
MIME 스니핑이란 브라우저가 특정 파일을 읽을 때 파일의 실제 내용과 Content-Type에 설정된 내용이 다르면 파일로 부터 형식을 추측하여 실행하는 것인데, 편리함을 위한 기능이지만 공격자에게 악용 될 가능성이 있다.
7. frameguard
X-Frame-Options 헤더를 설정하여 클릭재킹에 대한 보호를 제공한다.
클릭재킹이란 사용자가 자신이 클릭하고 있다고 인지하는 것과 다른 것을 클릭하도록 하여 속이는 해킹 기법이다. 속이기 위해 보이지 않는 레이어에 보이지 않는 버튼을 만드는 방법이 있다.