반응형
정말 오오오오오랜만에 글을쓴다
다시 잘 써보자고
가비지란?
- JVM의 힙영역에 할당됐던 메모리중 필요없게 된 메모리를 가비지라고 한다
- C언어의 경우 free() 함수를 통해 직접 메모리 해제
- 자바는 gc가 해준다
Person person = new Person();
person.setName("lsh");
person = null;
// 가비지 발생
person = new Person();
person.setName("ksh");
가비지 컬렉션 장점
- 개발자가 완벽하게는 신경쓰지 않아도 된다
가비지 컬렉션 단점
- 언제 메모리가 해제될지 개발자가 알 수 없다
- GC 동작중에는 STW, 오버헤드 발생
GC란
- 힙 영역에서 유효하지 않은(사용하지 않는) 메모리를 자동으로 수거하는 기능
- 힙 영역은 다음 두가지가 전제가 된다
- 대부분의 객체는 금방 unreachable 상태가 된다
- 오래된 객체 -> 새로운 객체로의 참조는 아주 적다
- 따라서 힙 영역은 객체의 생존 기간에 따라 Young 영역과 Old 영역으로 나눔

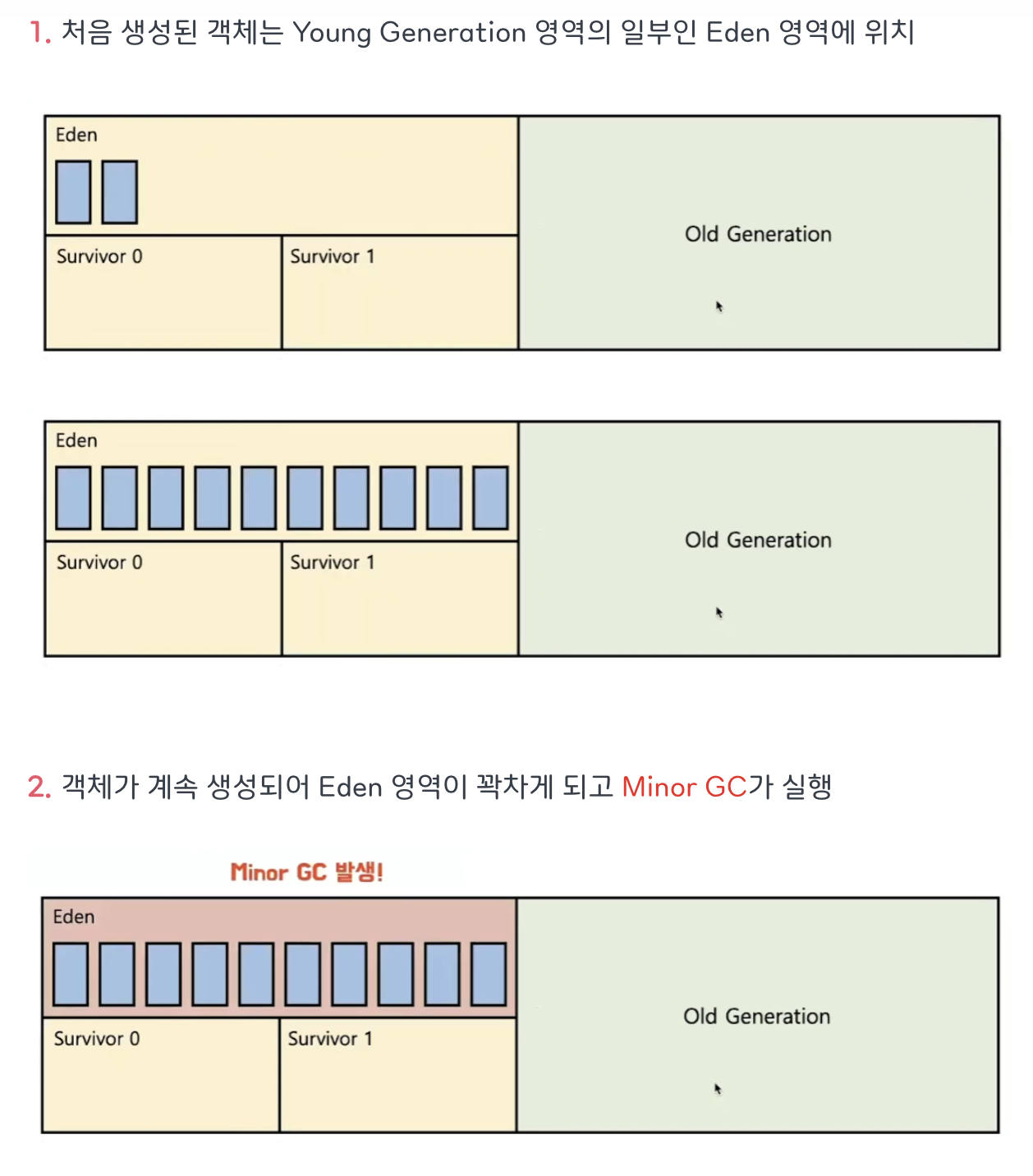
young영역
- young은 eden과 survivor1, 2로 구성
- eden
- eden은 new를 통해 새로 생성된 객체가 위치함
- 정기적인 gc 수행 후 살아남은 객체들은 survivor1,2로 넘김
- survivor
- 최소 1번 이상의 gc에서 살아남은 객체가 위치한 영역
- survivor1이나 survivor2중 하나는 꼭 비어있어야 한다
- eden
- 이곳에서의 gc 동작을 Minor gc라고함
old영역
- young영역에서 reachable 상태를 유지하여 살아남은 객체가 복사되어 이곳에 위치하게된다
- 이곳에서의 gc를 메이저gc 혹은 full gc라고함

- card table
- 예외적으로 old영역에 있는 객체가 Young영역에 있는 객체를 참조하는 경우도 있다
- 이럴때를 대비하여 512바이트의 덩어리(청크)로 되어있는 카드테이블이라는 것이 있다
- 마이너 gc가 발생할때 old영역에서 참조하는 young으로 참조하는 객체가 있는지 old영역을 확인안해도 되기에 효율적

왜 굳이 영역을 나누는가?
- heap 영역을 나누는 이유는 heap 전체를 탐색하여 메모리를 해제하는 full gc로 인한 성능상의 이슈를 최소화 시키기 위함
- weak generational hypothesis의 장점을 극대화 시키기 위함
- 주로 old 영역의 객체는 크기가 큰 것들이 대부분이고 gc 소요시간이 Minor gc보다 오래걸린다
- Minor gc와 Major gc의 비율간의 트레이드 오프
- survivor 영역을 두개로 나누는 이유는 메모리 단편화 문제를 해결하기 위함


GC 동작 방식
- young 영역과 old 영역의 세부적인 동작방식은 다르나 다음 두가지는 공통이다
- Stop the world
- gc 실행을 위해 jvm이 애플리케이션의 실행을 멈추는 작업
- gc를 실행하는 쓰레드를 제외한 모든 스레드가 중단됨
- gc튜닝은 대부분 이 시간을 줄이는것
- Mark and sweep
- 마크 -> 사용되는 메모리와 그렇지 않은 메모리를 식별하는 작업
- 스윕 -> 마크단계에서 사용되지 않는것으로 판별된 메모리를 해제하는 작업
- 컴팩션 -> 파편화된 메모리 영역을 앞에서부터 채워나가는 작업
- Stop the world

Minor GC 동작 방식
☕ 가비지 컬렉션 동작 원리 & GC 종류 💯 총정리
Garbage Collection(GC) 이란? 가비지 컬렉션(Garbage Collection, 이하 GC)은 자바의 메모리 관리 방법 중의 하나로 JVM(자바 가상 머신)의 Heap 영역에서 동적으로 할당했던 메모리 중 필요 없게 된 메모리 객
inpa.tistory.com


age란?
- Survivor 영역에서 객체가 gc로부터 살아남은 횟수
- 임계점에 다다르면 Promotion되어 old영역으로 이동한다
- JVM중 일반적인 HotSpot JVM의 경우 age 임계값이 31이다



Major GC 동작 방식
- young에서 age가 차서 넘어온 객체들
- old 영역의 메모리가 부족해지면 major gc 수행
- old 영역에서 한번에 삭제함
- old 영역은 young 영역보다 상대적으로 큰 공간을 가지고있기에 gc 수행시간 길다 → STW
- STW를 줄이기위해 여러 가비지 컬렉션 알고리즘이 존재
Minor Major GC 비교

- 만약 gc가 동작해도 모든 객체가 reachable해서 삭제될 객체가 없다면? → OOM 발생
GC 알고리즘
Serial GC
- 1 core cpu일때 사용하기위함
- Gc를 처리하는 스레드가 1개라서 STW시간이 제일 길다
- 실무에서 사용하는 케이스가 거의 없다고한다

Parallel GC
- 자바8의 default gc
- Minor gc를 멀티스레드로 수행함 (Major gc는 여전히 싱글스레드)
- Serial gc에 비해선 STW 감소
- 스레드는 기본적으로 cpu 개수만큼 할당됨

Parallel old GC
- Parallel gc를 개선함
- old영역에서도 멀티스레드로 메이저 gc수행
- Mark - summary - compact 방식

Cms GC
- 어플리케이션의 쓰레드와 GC 쓰레드가 동시에 실행되어 stop-the-world 시간을 최대한 줄이기 위해 고안된 GC
- 단, GC 과정이 매우 복잡해짐.
- GC 대상을 파악하는 과정이 복잡한 여러단계로 수행되기 때문에 다른 GC 대비 CPU 사용량이 높다
- 메모리 파편화 문제
- CMS GC는 Java9 버전부터 deprecated 되었고 결국 Java14에서는 사용이 중지

G1GC
- Java 9 이상부터 default GC
- 기존의 GC 알고리즘에서는 Heap 영역을 물리적으로 고정된 Young / Old 영역으로 나누어 사용하였지만, G1 gc는 아예 이러한 개념을 뒤엎는 Region이라는 개념을 새로 도입하여 사용.
- 전체 Heap 영역을 Region이라는 영역으로 체스같이 분할하여 상황에 따라 Eden, Survivor, Old 등 역할을 고정이 아닌 동적으로 부여
- Garbage로 가득찬 영역을 빠르게 회수하여 빈 공간을 확보하므로, 결국 GC 빈도가 줄어드는 효과를 얻게 되는 원리
- 이전의 GC들처럼 일일히 메모리를 탐색해 객체들을 제거하지 않는다.
- 대신 메모리가 많이 차있는 영역(region)을 인식하는 기능을 통해 메모리가 많이 차있는 영역을 우선적으로 GC 한다. → 영역(region)을 나눠 탐색하고 영역(region)별로 GC가 일어난다.
- 또한 이전의 GC 들은 Young Generation에 있는 객체들이 GC가 돌때마다 살아남으면 Eden → Survivor0 → Survivor1으로 순차적으로 이동했지만, G1 GC에서는 순차적으로 이동하지는 않는다.
- 대신 G1 GC는 더욱 효율적이라고 생각하는 위치로 객체를 Reallocate(재할당) 시킨다.
- 예를 들어 Survivor1 영역에 있는 객체가 Eden 영역으로 할당하는 것이 더 효율적이라고 판단될 경우 Eden 영역으로 이동시킨다.

ZGC
- Java 15에 release됨
- 대량의 메모리(8MB ~ 16TB)를 low-latency로 잘 처리하기 위해 디자인 된 GC
- G1의 Region 처럼, ZGC는 ZPage라는 영역을 사용하며, G1의 Region은 크기가 고정인데 비해, ZPage는 2mb 배수로 동적으로 운영됨. (큰 객체가 들어오면 2^ 로 영역을 구성해서 처리)
- ZGC가 내세우는 최대 장점 중 하나는 힙 크기가 증가하더도 STW의 시간이 절대 10ms를 넘지 않는다는 것

참고: GC 성능 비교
G1GC

- G1은 Garbage First 라는 뜻
- 조기 승격(Promotion)에 덜 취약하다. → old로 너무 빠르게 이동되는 문제 → STW
- 대용량 heap에서 확장성(특히 중단시간)이 우수하다.
- full STW GC를 없애거나 확 줄일 수 있다.
- Java 9 부터 default GC
- RSet(Remembered Set)을 통해 어떤 객체가 어떤 리전에 저장되어있는지 추적 가능 → 전체 힙을 뒤질필요가 없어짐
G1GC 동작 과정
- Initial Mark - SWT : Old 영역에서 존재하는 객체들이 참조하는 Survivor 영역을 찾는다. SWT가 발생한다.
- Root Region Scanning : Initial Mark 단계에서 식별한 Survivor 영역에서 Old 영역을 가리키는 레퍼런스를 식별한다.
- Concurrent Mark : 힙 전체에 걸쳐 접근 가능한 살아있는 객체를 찾는다.
- Remark - STW : Concurrent Mark 단계를 검증하고, 최종적으로 살아남을 객체들을 식별한다. 이 단계에서는 SATB(Snapshot-At-The-Beginning) 알고리즘이 사용된다. STW가 발생한다.
- Cleanup - STW : 어플리케이션을 멈추고(STW) 살아있는 객체가 가장 적은 리전에 대한 미사용 객체를 제거한다. 이후 STW를 끝내고, 앞서 GC 과정에서 완전히 비워진 리전을 FreeList에 추가하여 재사용할 수 있게 한다.
- Copy : GC 대상 리전이었지만 Cleanup 과정에서 완전히 비워지지 않은 리전의 살아남은 객체들을 새로운 리전에 복사하여 Compaction 작업을 수행한다.
gc튜닝
- 언제 튜닝해야하는가? → 성능저하의 원인이 명백히 gc때문일때
- 튜닝의 핵심은
- old영역으로 넘어가는 객체 최소화하기
- Major gc 시간 짧게 유지하기
즉, Major gc를 적게발생시키고, 발생했다면 빠르게 끝내야함
GC튜닝 방법
- 힙 크기 설정
- 힙이 크면 gc수행시간이 늘어남, 힙이 작으면 gc가 더 자주 수행됨 -> 잘 조절해야함
- Young영역과 Old영역 크기 비율 + Eden과 Survivor의 크기 비율
- old영역이 커지면 → Major gc가 자주발생하지않음 하지만 발생하면 오래걸림

G1GC 튜닝포인트
G1GC가 제공하는 파라미터가 많기에 튜닝 포인트도 많다
- Maximum GC Pause Time
- -XX:MaxGCPauseMillis 설정을 통해 GC 실행 중에 최대 일시 중지 시간을 지정함으로써 높은 지연 시간을 최소화 하거나 높은 처리량을 설정할 수 있다.
- Young Gen 사이즈 세팅을 하지 말 것(-XX:MaxGcPauseMillis 설정을 할 경우)
- -Xmn(new 영역)이나 -XX:NewRatio 설정을 피해야 한다.
- G1GC 알고리즘은 일시 중지 목표 시간을 충족하기 위해 Young 영역을 임의로 수정하게 되는데 Young 영역을 명시적으로 설정할 경우 일시 중지 목표 설정이 정상적으로 작동하지 않는다.
- 다른 GC 알고리즘에서 사용하던 JVM 인수 제거
- 기본적으로 G1GC의 경우 다른 GC 알고리즘(Serial, Parallel, CMS)에서 사용하던 JVM 인수와 같이 사용할 경우 G1GC의 파라미터가 정상적으로 동작하지 않을 수 있다.
- 문자열 중복 제거
- -XX:+UseStringDeduplication 설정을 통해 문자열 중복을 제거 한다.
- JDK 개발팀의 조사에 따르면 다음과 같은 자바 애플리케이션의 특징이 있다고 한다
- 프로세스의 25%는 문자열임
- 그 중 13.5%는 중복 문자열임
- 평균 문자열의 길이는 45자임
- 예를들어 멤버리스트 조회시 status가 “ACTIVE”라는 동일한 문자열이나 다 다른 메모리 공간 점유
그 외의 주요 파라미터

GC 튜닝보다 메모리 누수 예방이 우선
- 메모리 누수 : 사용되지 않는 객체들이 힙영역에 남아있는것
Static 변수에 의한 누수
- Static 변수는 클래스가 로드될때 생성되어 JVM이 종료될때까지 메서드 영역에 남아있는다 (사용 여부와 관계x)
- Static 변수가 객체를 참조 중이라면 해당 객체는 GC의 대상이 되지 않는다
- 더 이상 사용하지 않는다면 null을 할당하여 참조를 제거하자
무분별한 Autoboxing
public class Adder {
public long addIncremental(long l)
{
Long sum = 0L;
sum = sum + l;
return sum;
}
public static void main(String[] args) {
Adder adder = new Adder();
for(long i ; i < 1000 ; i++) {
adder.addIncremental(i);
}
}
}
컬렉션 클래스의 데이터를 해제하지 않는 경우
- List, Map, Set 같은 컬렉션 클래스들에 객체가 담겨있는 경우 객체의 참조가 해제되지 않음
- null 참조로 해제한다
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // 다 쓴 객체 참조 해제
return result;
}- Weak reference를 사용한다
- 특정 key 값이 더 이상 사용되지 않는다고 판단되면 해당 Key - Value 쌍을 삭제
- 자바에서 참조 종류는 다음 4가지가 있다
- 강한 참조(Strong Reference)
- 강한 참조는 Java의 기본 참조 유형으로 new 할당 후 새로운 객체를 만들어 해당객체를 참조하는 방식
- 강함 참조를 통해 참조되고 있는 객체는 참조가 해제되지 않는 이상 가비지 컬렉션의 대상에서 제외된다.
- 강한 참조(Strong Reference)
Object obj = new Object();
// 만약 GC 를 원한다면 명시적으로 null 표시를 해줘야 한다.
obj = null;- 약한 참조(Weak Reference)
- 약한 참조는 java의 lang 패키지의 WeakReference 클래스를 사용하여 생성한다.
- 약한 참조는 GC가 발생하면 무조건 수거된다.
- WeakReference가 사라지는 시점이 GC의 실행 주기와 일치한다.
Object obj = new Object();
WeakReference<Object> weakRef = new WeakReference<>(obj);
obj = null;
System.gc();
// 무조건 null 을 확인하게 된다.
System.out.println(weakRef.get());- Soft Reference
- Soft 참조는 강한 참조와 약한 참조와는 다르게 GC에 의해 수거될 수도 있고, 수거되지 않을 수도 있다.
- 메모리에 충분한 여유가 있다면 GC가 수행된다 하더라도 수거되지 않는다. 하지만 메모리가 부족하면 수거될 확률이 높다.
Object obj = new Object();
SoftReference<Object> softRef = new SoftReference<>(obj);
obj = null;
System.gc();
// GC 가 여유롭다면 해시코드를 확인할 수 있다.
System.out.println(softRef.get());- Phantom Reference?
- 가장 약한 참조 유형입니다.
- 객체 수거시에도 참조가 남아있는 참조 유형입니다.
- 객체의 finalize() 메서드가 호출된 직후에 GC 에 의해 수거됩니다.
- java.lang.ref PhantomReference class 로 만들 수 있습니다.
- 생성자에는 넣고자 하는 클래스와 함께 ReferenceQueue 를 인자로 받습니다.
- PhantomReference 는 객체가 참조되지 않습니다.
- 객체의 finalize 메서드가 호출된 직후 Phantom Reference 가 ReferenceQueue 에 등록됩니다.
- 이를 통해 객체의 finalize() 메서드가 호출되었음을 알 수 있습니다.
- 일반적으로 Phantom Reference 는 Native 객체나 Direct Memory 와 같이 JVM 에서 관리되지 않는 자원들을 해제하기 위해 사용됩니다.
CustomKey 사용으로 인한 누수
- Map을 사용할 때 custom key를 사용할 때는 equals()와 hashcode()를 값을 기반으로 구현해야한다
- 아래의 경우 Key값이 같은 객체로 인식하지 못해서 계속 Map에 쌓이게 되면서 메모리를 점유하게 된다
public class CustomKey {
private String name;
public CustomKey(String name) {
this.name=name;
}
public staticvoid main(String[] args) {
Map<CustomKey,String> map = new HashMap<CustomKey,String>();
map.put(new CustomKey("Shamik"), "Shamik Mitra");
}
}
해제되지 않은 리소스로 인한 누수
- close()나 try with resources 구문으로 리소스 반환해야함
public class Main {
public static void main(String[] args) {
try (FileWriter file = new FileWriter("data.txt")) { // 파일을 열고 모두 사용되면 자동으로 닫아준다
file.write("Hello World");
} catch (IOException e) {
e.printStackTrace();
}
}
}반응형
'Java' 카테고리의 다른 글
| [Java] Comparable과 Comparator로 객체 정렬하기 (1) | 2022.09.12 |
|---|---|
| [Java] 해시/해시테이블이란? (0) | 2021.07.12 |
| [Java] 제네릭(Generic) (0) | 2021.07.11 |
| [Java] Garbage Collection (4) | 2021.07.01 |
| [Java] Thread/MultiThread 4 - 동시성 문제 (0) | 2021.06.29 |























