또또 너무 오랜만에 글을 쓴다. 퇴근하면 왤케 피곤한걸까.
기존에 사용하던 stoplight에서 swagger로 전환하는 작업을 했다.
왜? 코드 안에서 바로 수정할 수 있기에 더 간편해서.
근데 한땀한땀 핸드메이드로 스웨거 주석을 작성하다가 스웨거 자동생성 라이브러리를 발견했고 그것을 사용해 보았다.
1. swagger란?
- Open Api Specification(OAS)를 위한 프레임워크이다.
- API들이 가지고 있는 스펙(spec)을 명세, 관리할 수 있는 프로젝트/문서
- API 사용 방법을 사용자에게 알려주는 문서
- express에서는 주석형태의 yaml형식으로 swagger 문서를 정의할 수 있다.
- URL에 /api-docs으로(내가 지정한) 접근하면 swagger가 만들어주는 페이지에 접근할 수 있다.
2. swagger 자동 생성 라이브러리 swagger-autogen
https://github.com/davibaltar/swagger-autogen
GitHub - davibaltar/swagger-autogen: This module performs the automatic construction of the Swagger documentation. The module ca
This module performs the automatic construction of the Swagger documentation. The module can identify the endpoints and automatically capture methods such as to get, post, put, and so on. The modul...
github.com
일반적인 express swagger 적용은 이미 다른 블로그에도 친절하게 잘 적혀있다.
하지만 api가 하나 추가될때마다 한땀 한땀 주석을 작성(혹은 복붙)하기엔 너무 귀찮을 것 같았다.
그래서 찾아본 결과 router가 위치한 파일의 경로를 알려주면 자동으로 해당 router를 인식하고,
그 밑에 딸린 router들도 인식하여 api 문서를 위한 json파일을 자동 생성해주는 라이브러리를 찾았다.
npm start를 한 후의 동작을 보자면
- package.json의 prestart 스크립트를 통해서 swagger.js를 실행한다. 이 파일은 지정된 경로에 존재하는 파일들에서 라우터와 swagger 주석들을 읽는다.
- swagger.js의 실행 결과로 swagger-output.json 파일이 생성된다. 이 파일은 우리가 생성할 swagger 문서의 구조를 나타낸다.
- 생성된 json을 바탕으로 swagger 문서가 생성된다.
주의사항.
swagger-output.json은 prestart 스크립트에 의해서 생성되기에 nodemon처럼 저장후 자동으로 서버가 재실행 되는 경우 prestart 스크립트가 실행 안될 수 있다.
즉, 서버를 완전히 종료하고 다시 npm start를 해줘야 prestart가 실행되며 swagger-output.json 파일이 생성(갱신)된다.
3. 적용하기
0. npm install
npm i swagger-ui-express swagger-autogen
1. 프로젝트 구조
├ src
└─ swagger
└─ swagger.js
└─ swagger-output.json
└─ loader
└─ express.ts
swagger.js을 prestart 스크립트로 실행하여 swagger-output.json을 얻어내고,
express.ts에서 swagger-output.json을 참조하여 swagger 문서를 생성하는 함수를 호출한다.
2. 코드
swagger.js
const swaggerAutogen = require('swagger-autogen')({ openapi: '3.0.0' });
const options = {
info: {
title: 'This is my API Document',
description: '이렇게 스웨거 자동생성이 됩니다.',
},
servers: [
{
url: 'http://localhost:3000',
},
],
schemes: ['http'],
securityDefinitions: {
bearerAuth: {
type: 'http',
scheme: 'bearer',
in: 'header',
bearerFormat: 'JWT',
},
},
};
const outputFile = './src/swagger/swagger-output.json';
const endpointsFiles = ['./src/loaders/express.ts'];
swaggerAutogen(outputFile, endpointsFiles, options);securityDefinitions 부분은 JWT를 위한 설정이다.
저 속성을 지정하면 authorize라는 버튼이 생기며 JWT Access Token을 header에 등록할 수 있다.
여러 api들을 요청하고 응답을 확인하기위해 일일이 Access Token을 넣어줄 필요가 없다.
보다시피 outputFile의 경로를 지정해 주었고 swagger middleware를 설정할 때 이곳을 참조하면 된다.
endpointsFiles는 router가 위치한 파일이다. 나의 경우 이곳에 최상단 router가 있기에 이곳을 지정했다.
├ /api
└─ /user
└─ /
└─ /marketing
└─ /phone
└─ /board
└─ /
└─ /admin
└─ /ping
이와 같은 router구조를 가진다고 했을 때, /api가 위치한 곳을 가리켜야 swagger가 만들어졌을때
/api/user/phone이렇게 전체 경로가 표시된다.
아무튼 이렇게 생성된 json파일을 가지고 swagger를 생성해준다.
import swaggerFile from '../swagger/swagger-output.json';
import swaggerUi from 'swagger-ui-express';
//Swagger
app.use('/api-docs', swaggerUi.serve, swaggerUi.setup(swaggerFile, { explorer: true }));
이제 /api-docs로 접속하면 다음과 같은 화면을 볼 수 있다.
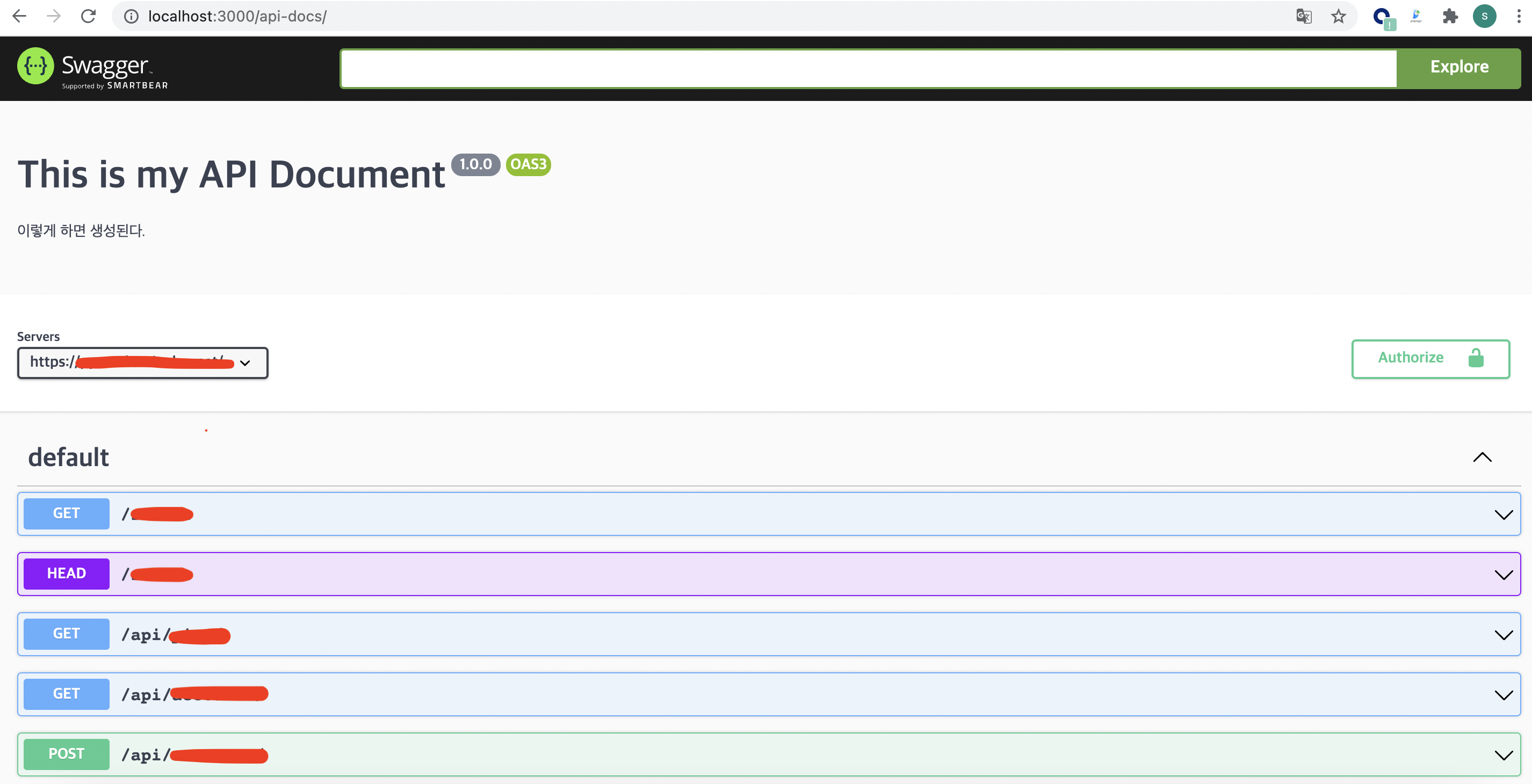
근데 지금은 모든 api들이 무질서하게 나열돼 있어서 보기 안좋다.
tag를 걸어보자.
tag를 걸면서 request, response 양식도 정해주자.
다음과 같은 주석을 각 api 함수 내부에 넣어주자. 이게 좀 가독성을 해칠 수 있겠지만 그나마 가장 간단하고 편리한 방법이라고 생각한다...
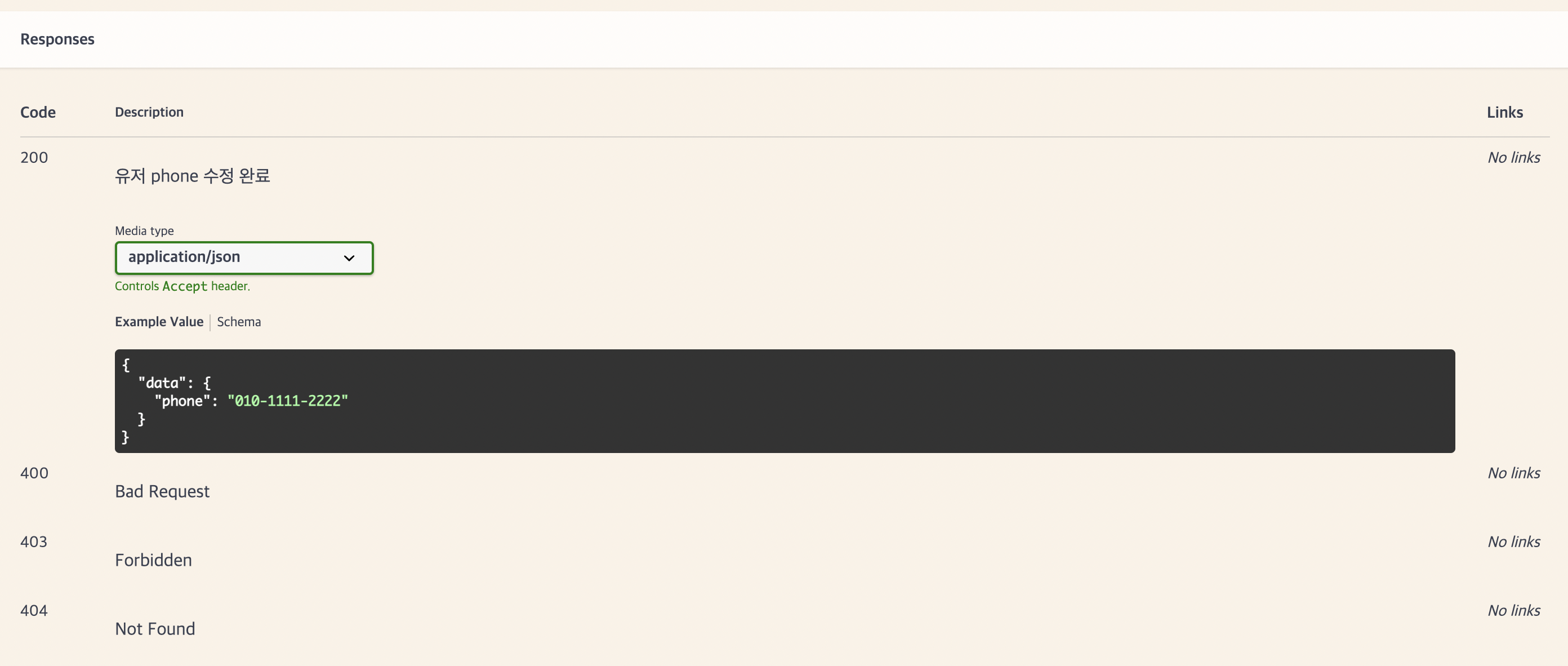
다음 api는 user의 phone을 수정하는 put api이다.
/*
#swagger.tags = ['Users']
#swagger.summary = '유저 phone 수정'
#swagger.description = '유저 phone을 업데이트한다.'
#swagger.security = [{
"bearerAuth": []
}]
#swagger.requestBody = {
required: true,
content: {
"application/json": {
schema: {
"type": "object",
"properties": {
"phone": {
"type": "string",
"required": false
}
}
},
example: {
"phone": "010-1111-2222",
},
},
}
}
#swagger.responses[200] = {
description: "유저 phone 수정 완료",
content: {
"application/json": {
schema: {
"data": {
"phone": "010-0000-0000",
}
},
example: {
"data": {
"phone": "010-1111-2222",
}
},
}
}
}
*/
태그를 Users로 지정한 것들은 다음과 같이 이쁘게 그룹화된다.

또 요청/응답 형식의 예시를 지정해 둘 수 있다.
이렇게 하면 다른 개발자들과 협업하기 편리할 것이다.
나의 경우는 api 함수 내부 가독성을 최대한 살리기위해 200 응답만 예시를 정해두었고 나머지는 생략했다.
추가적인 속성들은 위에 첨부한 swagger-autogen 공식 깃허브 문서를 참고하면 쉽게 따라할 수 있을 것이다.
4. 마치며
나는 응애개발자라 아직 주석이 가득한 코드가 익숙하지 않다.
자바의 경우 어노테이션으로 깔끔 세련되게 됐던거같은데 노드는 좀 애매한 것 같다..
처음부터 swagger 자동 생성을 찾아볼걸, 괜히 한땀 한땀 주석만 쓰고있느라 시간낭비 한 것 같다. 큿소!
'NodeJS' 카테고리의 다른 글
| [Redis] Redis로 분산락 구현하기 (0) | 2023.04.14 |
|---|---|
| [NodeJS] Sequelize로 마이그레이션 진행하기 (0) | 2022.03.19 |
| [NodeJS] 기본값 파라미터(default parameter value) (0) | 2021.10.29 |
| [NodeJS] Jest mock을 사용한 단위테스트 (0) | 2021.09.27 |
| [NodeJS] tsconfig.json에 대해 알아보자 (0) | 2021.09.25 |