1. 왜 RabbitMQ를 사용하는가?
RabbitMQ는 *AMQP를 따르는 오픈소스 메세지 브로커이다.
RabbitMQ는 데이터를 잠시 보관하고 나중에 비동기적으로 처리하고 싶을 경우 사용
*AMQP: Advanced Message Queing Protocol의 약자로, 흔히 알고 있는 MQ의 오픈소스에 기반한 표준 프로토콜
실생활에서 예를 들어보자
스타벅스에서 손님들이 줄을 서서 커피를 주문한다.
1. 메시지 큐X
첫번째 손님이 커피를 주문하면 첫번째 손님의 커피가 완성될때까지 두번째 손님은 계속 줄을 서서 대기해야한다.
2. 메시지 큐O
첫번째 손님은 커피를 주문하고 자리로 간다. 두번째, 세번째 손님들도 주문서만 던져놓고 자리로 간다.
이때 손님(프로듀서)들이 바리스타(컨슈머)에게 던져놓는 주문서가 메시지가 되고 주문서가 쌓여가는 곳이 메시지 큐가 된다.
이런 구조는 커피를 비동기적으로 만들기에 효율적이며,
주문서는 바리스타에게 전달될때 까지 잠시 저장되기에 바리스타가 까먹거나 하는 주문 누락이 발생하지 않는다.
정리하자면
메시지를 많은 사용자에게 전달해야할 때
요청에 대한 처리시간이 길어 해당 요청을 다른 API에 위임하고 빠른 응답처리가 필요할 때
애플리케이션 간 결합도를 낮춰야 할 때
RabbitMQ를 사용한다
2. RabbitMQ는 어떻게 이루어져있는가?
[프로듀서 → 브로커(익스체인지+큐) → 컨슈머]
의 구조로 메시지를 전달해주는 메시징 서버
RabbitMQ는 다음과 같이 구성된다.
Producer: 메시지를 보내는 놈
Exchange: 메시지를 알맞은 큐에 전달해주는 놈
Queue: 메시지를 차곡차곡 쌓아두는 놈
Consumer: 메시지를 받는 놈
위 그럼처럼 Producer는 Queue에 직접 메시지를 전달하는 것이 아니다.
[프로듀서 → 익스체인지 → 큐 → 컨슈머]의 절차를 밟는다.
Exchange에서 알맞은 Queue로 메시지를 분배한다.(Exchange들과 Queue들은 바인딩되어있다)
무슨 기준으로 분배하느냐?
Exchange Type에 따라 다르다.
Exchange Type 4가지
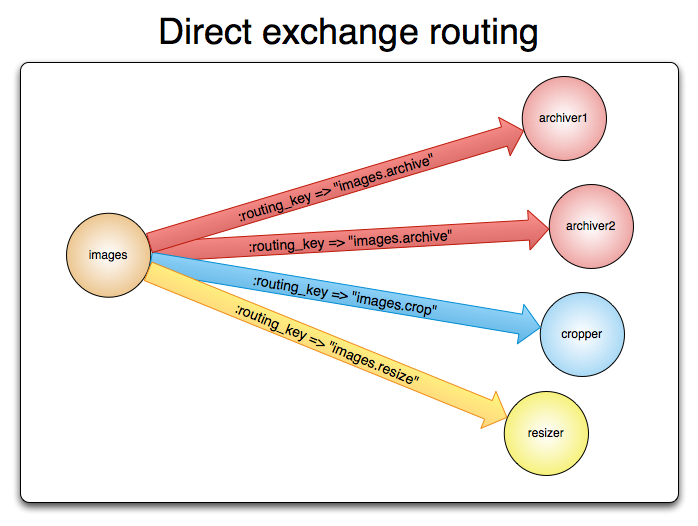
메시지에 포함된 Routing Key를 기반으로 특정 Queue에 메시지를 하나씩 전달한다.
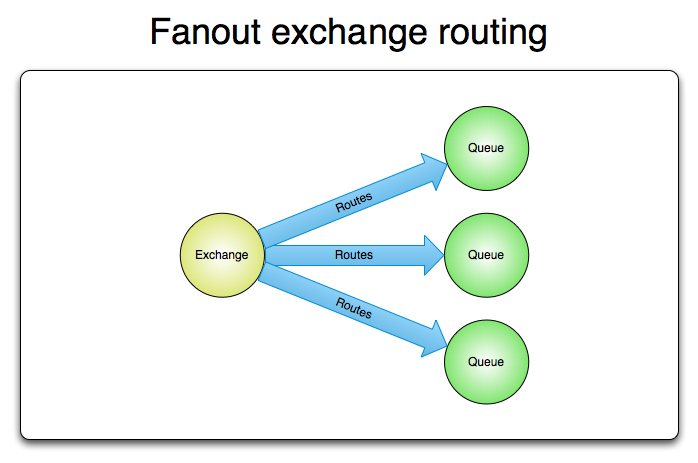
Fanout
Routing Key에 상관 없이 연결돼있는 모든 Queue에 동일한 메시지를 전달한다.
라우팅키를 평가할 필요가 없기때문에 성능적인 이점이 있다.
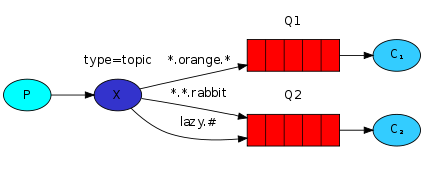
Topic
라우팅키 전체가 일치하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달된다.
Topic Exchange 에서 사용하는 binding key 는 점(.)으로 구분된 단어를 조합해서 정의한다.
* 와 #을 이용해 와일드 카드를 표현할 수 있으며, * 는 단어 하나 일치 # 는 0 또는 1개 이상의 단어 일치를 의미한다.
다음과 같이 binding key 를 정의한 경우에 메시지의 routing key 가 quick.orange.rabbit 또는 lazy.orange.elephant 이면, Q1, Q2 둘 다 전달된다. lazy.pink.rabbit 는 binding key 2개와 일치 하더라도 1번만 전달된다.
quick.brown.fox, quick.orange.male.rabbit 는 일치하는 binding key 가 없기 때문에 무시된다.
Header
메시지 속성 중 headers 테이블을 사용해 특정한 규칙의 라우팅을 처리한다.
x-match = any 일 경우 헤더 테이블 값 중 하나가 연결된 값 중 하나와 일치하면 메시지 전달
x-match = all 일 경우 모든 값이 일치해야 메시지를 전달한다.
추가적인 사용 패턴들은 다음 블로그에 잘 설명이 되어있더라.
https://hamait.tistory.com/402
RabbitMQ 사용패턴들
역주: 메세지큐에 대한 글을 적기 전에 왜 메세지큐냐? 를 먼저 생각해봐야한다. 메세지큐는 그냥 메세지를 전달해주는 서버인건데, 기술자체에 집중할 필요는 나중에 생각해보고 , 처음 생각해
hamait.tistory.com
3. Connection과 Channel
Connection
RabbitMQ에서 지원하는 모든 프로토콜은 TCP 기반이다.
효율성을 위해 긴 연결을 가정한다. (프로토콜 작업당 새 연결이 열리지 않음.)
하나의 클라이언트 연결은 단일 TCP 연결을 사용한다.
클라이언트가 연결을 성공하려면, RabbitMQ 대상 노드는 특정 프로토콜에 대한 연결을 허용해야 한다.
연결은 오래 지속되어야 하기 때문에 일반적으로 구독을 등록하고, 폴링 대신에 메시지를 전달하여 소비한다.
연결이 더 이상 필요하지 않은 경우, 리소스 절약을 위해 연결을 닫아야 한다. 이를 수행하지 못하는 클라이언트는 리소스의 대상 노드를 고갈시킬 위험이 있다.
운영 체제는 단일 프로세스가 동시에 열 수 있는 TCP 연결(소켓) 수에 대한 제한이 있다. QA 환경에서는 충분한 경우가 있지만, Production 환경에서는 더 높은 제한을 사용하도록 구성해야 할 수도 있다.
Channel
단일 TCP 연결을 공유하는 논리적인 개념 의 경량 연결로 다중화된다.
클라이언트가 수행하는 모든 프로토콜 작업은 채널에서 발생한다.
채널 안에 연결할 Queue를 선언할 수 있으며, 채널 하나당 하나의 Queue만 선언이 가능하다.
채널은 Connection Context에만 존재하기 때문에 Connection이 닫히면, 연결된 모든 채널도 닫힌다.
클라이언트에서 처리를 위해 멀티 프로세스/스레드를 사용한다면, 프로세스/스레드 별로 새 채널을 열고 공유하지 않는 것이 일반적이다.
아무튼.
Connection: Application과 RabbitMQ Broker사이의 물리적인 TCP 연결
Channel: connection내부에 정의된 가상의 연결. queue에서 데이터를 손볼 때 생기는 일종의 통로같은 개념
한개의 Connection에 여러개의 Channel,
한개의 Channel에 한개의 Queue
https://hyos-dev-log.tistory.com/8
RabbitMQ의 Connection과 Channel
사내에서 진행되는 서비스를 개편하게 되면서, RabbitMQ를 사용하게 되었습니다. RabbitMQ을 사용하고, 운영하면서 Connection과 Channel에 대한 개념이 잡히지 않아서 정리하게 되었습니다. Connection 일반
hyos-dev-log.tistory.com
4. 적용하기
NodeJS에 적용하기
1. 초기 설정
amqp.connect함수를 통해서 Rabbitmq에 연결한다.
export async function makeConnection ( const await protocol username password hostname port vhost '/' heartbeat 0
2. NodeJS에서 메시지 Subscribe하기
const protocol username password hostname port vhost '/' heartbeat 0 export async function listenForResults ( try const await const await await 1 const await await 1 console 'start consuming messages from web service' await await catch (1) connection 획득
(2) connection으로부터 channel을 생성
(3) consume 실행
위 1, 2, 3번의 과정은 서버가 최초 실행될때 실행된다.
*Prefetch란, 큐의 메시지를 컨슈머의 메모리에 쌓아놓을 수 있는 최대 메시지의 양
https://minholee93.tistory.com/entry/RabbitMQ-Prefetch
[RabbitMQ] Prefetch
이번 글에서는 RabbitMQ의 Prefetch에 대해 알아보겠습니다. 1. Prefetch란? Queue의 메세지를 Consumer의 메모리에 쌓아놓을 수 있는 최대 메세지의 양 입니다. 예를 들어 Prefetch가 250일 경우, RabbitMQ는 250..
minholee93.tistory.com
export function myConsume1 ( { connection, myChannel1 } ) return new Promise ( resolve, reject ) => 'q1' async function ( msg ) console 'myConsume1' const const JSON await 'close' err => return 'error' err => return
(4) 메시지 파싱
(5) 원래 수행하고자 했던 로직 실행
ack를 전송하지 않고 소비자가 죽거나 (채널이 닫히거나 연결이 끊어 지거나 TCP 연결이 끊어지는 경우),
RabbitMQ는 메시지가 완전히 처리되지 않았 음을 인식하고 다시 대기 한다.
즉 컨슈머(소비자)가 사망했을 경우를 대비
3. NodeJS에서 메시지 Publish하기
export let export async function makeConnection ( const await protocol username password hostname port vhost '/' heartbeat 0 await export async function publishToChannel ( channel, { exchangeName, routingKey, data } ) await JSON 'utf-8' persistent true (1) 서버 최초 실행시 makeConnection 메소드를 사용하여 연결한다
(2) channel당 하나의 queue만 생성이 가능하기에 필요한 큐만큼의 채널을 생성하고 전역변수로 export해준다
(3) channel의 publish메소드를 사용하는 함수를 만든다
(1), (2)의 과정은 서버가 최초 실행될때 실행된다.
RabbitMQ가 종료되거나 충돌하면 사용자가 알리지 않는 한 대기열과 메시지를 잃게된다. 메시지가 손실되지 않도록하려면 큐와 메시지에 durable과 persistent 설정을 주어야한다.
즉, ack과 달리 RabbitMQ가 사망할 경우를 대비
https://skarlsla.tistory.com/13
[RABBITMQ] persistent, durable, ack
1. 메시지 수신 자동 확인(ack , noAck) 작업을 수행하는 데 몇 초가 걸릴 수 있습니다. 소비자 중 한 명이 긴 작업을 시작하고 부분적으로 만 수행되어 사망하는 경우 어떻게되는지 궁금 할 수 있습
skarlsla.tistory.com
const await exchangeName 'ex1' routingKey 'p1' data uid
(4) 이후 메시지를 publish할 곳에서 export한 channel과 설정값을 publish함수의 인자로 넣어주며 사용한다.
Spring에서 사용하기
1. 초기설정 - application.yml
spring:
rabbitmq:
host: somethingsomethingaddress.mq.region.amazonaws.com
port: 5671
username: myname
password: mypassword
ssl:
enabled: true
2. Spring에서 메시지 Subscribe하기
@RabbitListener(queues = [ "sample.queue" ]) public fun receiveMessage (message : Message ) out "수신받은 메시지는 $message "
조금 더 자세한 설정을 하려면 어노테이션에 옵션을 추가해주면 된다.
@RabbitListener(bindings = [QueueBinding(
value = Queue(value = "q1" ) "ex1" fun receiveMessage (message : Message ) out "수신받은 메시지는 $message "
https://cheese10yun.github.io/spring-rabbitmq/
Rabbit MQ 기초 사용법 - Yun Blog | 기술 블로그
Rabbit MQ 기초 사용법 - Yun Blog | 기술 블로그
cheese10yun.github.io
https://syaku.tistory.com/?page=7
개발자 샤쿠 @syaku
Full Stack Web Developer.
syaku.tistory.com
3. Spring에서 메시지 Publish하기
val val "ex1" "p2" (1) 생성자 주입
(2) 보낼 메시지를 dto로 포장해서 objectMapper.writeValueAsString 로 직렬화해서 전송한다.
5. 그 외 읽어보면 좋을 RabbitMQ 관련 이모저모
1. RabbitMQ에서 최적을 성능을 뽑는 팁?
https://kamang-it.tistory.com/627
[AMQP][RabbitMQ]RabbitMQ그리고 Work Queue의 사용법 - (3)
참고 [AMQP][RabbitMQ]RabbitMQ를 사용하는 이유와 설치방법 - (1) [AMQP][RabbitMQ]RabbitMQ아주 기초적이게 사용하기 - Java(feat.Hello World!) - (2) https://www.rabbitmq.com/tutorials/tutorial-two-java...
kamang-it.tistory.com
2. Spring boot Exchange와 Queue 자동 생성 이해
스프링 부트가 구동될때 exchange와 queue 설정에 따라 자동으로 생성되지 않는 다.
자동 생성 시점은 메시지가 발행이 될때와 메시지를 구독하기 위해 RabbitMQ 서버에 연결될때 생성된다.
아래 설정은 자동 생성 여부를 설정하기 위한 옵션이고 기본 값은 true 이다.
spring.rabbitmq.dynamic=true https://syaku.tistory.com/?page=7
개발자 샤쿠 @syaku
Full Stack Web Developer.
syaku.tistory.com
3. kafka vs RabbitMQ
앞선 내용들을 통해 각각의 정의 및 프로세스에 대해 면밀히(?) 살펴봤다.kafka 와 RabbitMQ 의 차이에 대해 어느정도 이해할 수 있겠지만 본 글의 주제가 주제인만큼 다시 한번 간단히 정리해보도록 하겠다.
kafka 는 pub/sub 방식 / RabbitMQ 는 메시지 브로커 방식kafka 의 pub/sub방식은 생산자 중심적인 설계로 구성. 생성자가 원하는 각 메시지를 게시할 수 있도록 하는 메시지 배포 패턴으로 진행RabbitMQ 의메시지브로커방식은 브로커 중심적인 설계로 구성. 지정된 수신인에게 메시지를 확인, 라우팅, 저장 및 배달하는 역할을 수행하며 보장되는 메시지 전달에 초점전달된 메시지에 대한 휘발성RabbitMQ 는 queue에 저장되어 있던 메시지에 대해 Event Consumer가져가게 되면 queue에서 해당 메시지를 삭제한다.kafka 는 생성자로부터 메시지가 들어오면 해당 메시지를 topic으로 분류하고 이를 event streamer에 저장한다. 그 후, 수신인이 특정 topic에 대한 메시지를 가져가더라도 event streamer는 해당 topic을 계속 유지하기 때문에 특정 상황이 발생하더라도 재생이 가능하다.
용도의 차이kafka 는 클러스터를 통해 병렬처리가 주요 차별점인 만큼 방대한 양의 데이터를 처리할 때, 장점이 부각된다.RabbitMQ 는 데이터 처리보단 Manage UI를 제공하는 만큼 관리적인 측면이나, 다양한 기능 구현을 위한 서비스를 구축할 때, 장점이 부각된다.
https://velog.io/@cho876/%EC%B9%B4%ED%94%84%EC%B9%B4kafka-vs-RabbitMQ
카프카(kafka) vs RabbitMQ
오늘은 kafka와 RabbitMQ의 차이에 대해 알아보도록 하겠다. 1. 이해 1-1. 메시지 큐(MessageQuque : MQ) kafka와 rabbitMQ를 이해하기 위해선 우선 메시지 큐에 대한 이해가 선제적으로 필요하다. >메시지 큐(Mes
velog.io
둘다 쩌는 솔루션이다. - RabbitMQ 가 좀더 성숙하다. (Written 12 Sep, 2012 )
철학은 좀 다른데, 기본적으로 RabbitMQ 는 브로커 중심적이며, 생산자와 소비자간의 보장되는 메세지 전달에 촛점을 맞추었다.
반면 Kafka 는 생산자 중심적이며, 엄청난 이벤트 데이터을 파티셔닝하는데 기반을 둔다. 배치 소비자를 지원하며, 온라인, 오프라인에 저 지연율(Low latency)을 보장하며 메세지를 전달해준다.
RabbitMQ 는 브로커상에서 전달 상태를 확인하기위한 메세지 표식을 사용한다. 카프카는 그런 메세지 표식이 없으며 컨슈머가 전달(배달) 상태를 기억하는것을 기대한다.
둘다 클러스터간의 상태를 관리하기위해 Zookeeper 를 사용한다.
RabbitMQ 는 커다란 크기의 데이터를 위해 디자인되지 않았으며 만약 컨슈머가 매우 느리다면 실패할것이다.그러나 post 2.0 에 RabbitMQ 는 느린 배치 컨슈머를 핸들링 되는게 요청되어졌다.
Kafka 은 오직 토픽같은 exchanges 를 사용한다. RabbitMQ 는 다양한 exchanges 를 사용한다.
Kafka 는 파티션들 안에서 메세지 순서를 제공하며, 파티션들간에 엄격한 순서를 가진다. 카프카 컨슈머들은 충분히 스마트해야하며 , 그들 스스로 파티션간의 순서를 해결(resolve) 해야한다.
Kafka 는 디스크상에서 메세지를 저장하고 데이타 손실을 막기위해 클러스터로 그들을 복제한다. 각각의 성능에 큰 문제없이 브로커는 테라바이트를 핸들링할수있다. Kafka 는 쓰기에 초당 200k 메세지를 , 읽는데는 3M 메세지를 제공되도록 테스트되었다.
https://hamait.tistory.com/403?category=138704
카프카(Kafka) vs RabbitMQ
생산자 (Sender) 테스트 결과 이유 카프카 생산자는 브로커로 부터의 ack 를 기다리지 않고 메세지를 보낸다.브로커가 핸들링 할수있는 만큼 빠르게 메세지를 마구 보낸다. 카프카는 좀더 효율
hamait.tistory.com
참고:
더보기
https://sg-choi.tistory.com/406
[RabbitMQ] RabbitMQ란?
RabbitMQ란? RabbitMQ는 AMQP를 따르는 오픈소스 메세지 브로커 AMQP는 클라이언트가 메시지 미들웨어 브로커와 통신할 수 있게 해주는 메세징 프로토콜 주요 개념으로 Producer, Exchange, Binding, Queue, Consu..
sg-choi.tistory.com
https://jin2rang.tistory.com/entry/RabbitMQ%EB%9E%80
RabbitMQ란?
RabbitMQ란? 서버간 메세지를 전달해주는 오픈소스 메세지 브로커이다. A → B에게 또는 A → B,C,D,E,F ... 등 메세지를 보내려고 할 때 RabbitMQ가 이 메세지를 받아서 전달 해주는 것으로 이해하면 된다
jin2rang.tistory.com
https://velog.io/@cckn/%EB%B2%88%EC%97%AD-RabbitMQ-%EB%B0%8F-Node.js%EB%A5%BC-%EC%82%AC%EC%9A%A9%ED%95%9C-%EB%B9%84%EB%8F%99%EA%B8%B0-%EB%A7%88%EC%9D%B4%ED%81%AC%EB%A1%9C-%EC%84%9C%EB%B9%84%EC%8A%A4
(번역) RabbitMQ 및 Node.js를 사용한 비동기 마이크로 서비스
메세지와 이벤트를 통한 확장성과 내결함성.이 글은 Asynchronous Microservices with RabbitMQ and Node.js를 번역한 글입니다
velog.io
https://daily-coding-diary.tistory.com/13
[Node.js] RabbitMQ
목표 : RabbitMQ를 이용하여, 데이터를 임시로 저장하고 확인해봅시다. RabbitMQ는 디비 또는 데이터 처리에 문제가 생겼을때 데이터를 임시로 처리해줄때 많이 사용합니다. 예를 들면, 채팅방에 한
daily-coding-diary.tistory.com
https://www.joinc.co.kr/w/man/12/%EC%95%84%ED%82%A4%ED%85%8D%EC%B3%90/Message#sid_1
스타벅스로 살펴보는 Message 아키텍처
소프트웨어 시나리오
www.joinc.co.kr