클레이튼 기반의 dapp을 개발하며 블록체인의 트랜잭션과 서비스의 데이터베이스간의 싱크를 보장해야하는 상황을 마주했다.
성공한 트랜잭션이면 관련 정보를 데이터베이스에 반영해주고,
실패한 트랜잭션이면 관련 정보를 데이터베이스에 반영해주지 않는, 그런 요구사항이었다.
클레이튼 블록체인에서 자체적으로 실패한 트랜잭션에 대한 롤백은 시켜주기에 클레이튼의 성공여부를 먼저 확인하고 데이터베이스 반영 여부를 정해야했다. [클레이튼 트랜잭션] -> [데이터베이스 트랜잭션]의 플로우였기에 이 사이에 트랜잭션의 성공여부만 확인하고 데이터베이스의 트랜잭션을 발생시킬지 말지 결정하면 됐다.
[클레이튼 트랜잭션] -> [트랜잭션이 성공했는지 확인] -> [데이터베이스 트랜잭션]
하지만 블록체인은 트랜잭션이 확정되기까지 걸리는 시간인 Finality라는 개념이 있기에 트랜잭션의 성공 여부를 조회하려면 이 Finality 시간 이후에 해야했다. 클레이튼의 경우 이 시간이 평균 1초라고 알려져있다. 평균이기에 실제 상황에서 약간의 오차는 있을 것 이다. 따라서 Finality만큼의 딜레이를 하고 트랜잭션 조회 -> 데이터베이스 트랜잭션 실행의 절차를 밟아야 했다.
즉, 필요한 조건은
1. 트랜잭션 조회에 delay를 줘야한다. -> Finality 때문에
2. 적어도 2회 이상 retry를 하며 조회해야한다. -> Finality 시간이 일정하지 않기 때문에
3. 최대한 빠르게 트랜잭션의 성공 여부를 판단해야한다. -> 원활한 서비스 제공을 위해
2. 고려했던 선택지
세가지를 고려했었다. 참고로 NodeJS로 개발했다.
1. 스케줄러를 통해 짧은 간격으로 확정되지 않은 트랜잭션들의 성공 여부를 조회하기
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다.
NodeJS의 스케줄러를 통해서 is_confirmed가 false인 기록들을 짧은 간격으로 주기적으로 조회하며 트랜잭션의 성공 여부를 확인한다.(트랜잭션 성공여부는 caverExtKAS 라이브러리의 getTransferHistoryByTxHash 함수를 사용했다)
문제점.
트랜잭션이 발생하지 않을때도 몇 초마다 항상 실행되기에 리소스 낭비라고 생각됐다.
2. 클레이튼 이벤트 리스너를 통해 트랜잭션이 수행될 때 발생되는 이벤트를 추적하여 판별하기
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다.
트랜잭션이 성공하면 열어둔 소켓을 통해 클레이튼 이벤트를 Listen할 수 있는데 트랜잭션이 성공하면 이벤트가 수신되므로(아마..?) 수신했다는 것은 해당 트랜잭션이 성공했다는 의미.
문제점.
가끔 성공한 트랜잭션의 이벤트가 리슨되지 않을때가 있었다. (왜일까..)
3. RabbitMQ를 통해서 딜레이와 재시도 기능을 구현하여 조회하기 (이 방법을 사용했다)
트랜잭션을 발생시킬 때 transaction_history 테이블에 트랜잭션의 발생 여부를 기록해두고 is_confirmed는 false로 둔다. 또 동시에 RabbitMQ로 발생한 트랜잭션의 정보를 publish한다.
컨슈머에서 이를 구독하고 이 시점에 트랜잭션 성공 여부를 조회한다.
트랜잭션이 성공이면 데이터베이스에도 관련 정보를 반영 후 ack으로 마무리하고, 실패면 retry_count를 1추가해서 DLX로 보낸다. 이곳에서 5000ms동안 대기하고 다시 작업큐로 메시지를 보내서 반복한다.(넉넉히 5초로 딜레이를 주었다)
3번에서 반복 횟수동안 모두 트랜잭션이 확정이 안됐거나 실패 판정이 나면 데이터베이스에 관련 정보를 반영하지 않고 ack을 반환한다.
이 방법을 선택한 이유
RabbitMQ를 통해서 사용자가 몰릴때 비동기적으로 안정적인 로직 수행이 가능하기에
RabbitMQ의 Durability를 통해 중요한 정보를 잃어버리지 않을 수 있기에
RabbitMQ의 DLX 기능을 통해 딜레이와 재시도를 구현할 수 있기에
3. RabbitMQ 구성
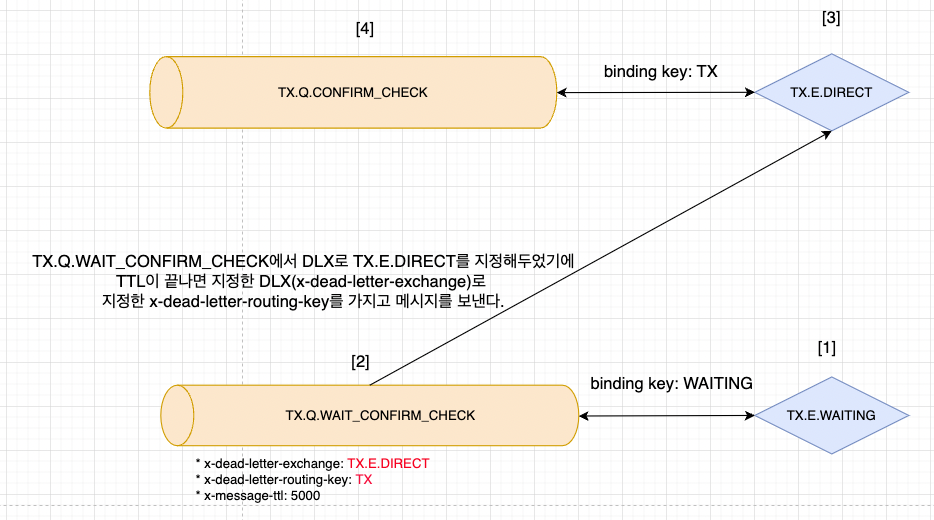
RabbitMQ는 위와같이 구성해보았다.
[1], [2]
클레이튼 트랜잭션을 발생시킴과 동시에 트랜잭션의 정보와 retry_count를 담은 메시지를 publish한다.
[3], [4]
지정한 익스체인지에서 지정한 큐로 메시지를 전달한다.
[5]
트랜잭션의 성공 여부를 확인하는 컨슈머에서 트랜잭션의 성공 여부를 확인한다.
성공이라면 서비스 로직을 실행하고 ack을 반환한다.
[6]
트랜잭션이 아직 확정되지 않았거나 실패했다면 WAITING 익스체인지로 같은 메시지를 그대로 전달한다.
이때마다 retry_count에 1 씩 더해서 전달한다.
[7]
전달된 메시지는 TX.Q.WAIT_CONFIRM_CHECK 큐로 보내지는데 이 큐는 DLX와 TTL 설정이 돼있다.
[8]
지정한 TTL 시간이 지나면 메시지가 x-dead-letter-exchange로 지정된 익스체인지로 x-dead-letter-routing-key 바인딩 키를 사용해서 전달된다.
즉, 이 큐에서 5000ms 동안 대기하고 TX.E.DIRECT 익스체인지로 가게된다.
이때 바인딩키는 TX를 가지고간다.
TX는 TX.E.DIRECT와 TX.Q.CONFIRM_CHECK의 바인딩키다.
따라서 TX.E.DIRECT 익스체인지에 도착한 메시지는 TX.Q.CONFIRM_CHECK 큐로 다시 보내진다.
[4], [5], [6], [7], [8]의 과정을 최대 3번까지 반복하고도 트랜잭션이 실패라고 판별되면 최종적으로 실패처리(데이터베이스에 반영하지 않기)를 한 후 ack를 반환한다.
RabbitMQ는 데이터를 잠시 보관하고 나중에 비동기적으로 처리하고 싶을 경우 사용하는 일종의 데이터 저장소이다.
*AMQP:Advanced Message Queing Protocol의 약자로, 흔히 알고 있는 MQ의 오픈소스에 기반한 표준 프로토콜
실생활에서 예를 들어보자
스타벅스에서 손님들이 줄을 서서 커피를 주문한다.
1. 메시지 큐X
첫번째 손님이 커피를 주문하면 첫번째 손님의 커피가 완성될때까지 두번째 손님은 계속 줄을 서서 대기해야한다.
2. 메시지 큐O
첫번째 손님은 커피를 주문하고 자리로 간다. 두번째, 세번째 손님들도 주문서만 던져놓고 자리로 간다. 바리스타는 쌓여가는 주문서들을 보며 순서대로 커피를 만든다. 커피가 만들어지면 손님들이 받아간다.
이때 손님(프로듀서)들이 바리스타(컨슈머)에게 던져놓는 주문서가 메시지가 되고 주문서가 쌓여가는 곳이 메시지 큐가 된다.
이런 구조는 커피를 비동기적으로 만들기에 효율적이며,
주문서는 바리스타에게 전달될때 까지 잠시 저장되기에 바리스타가 까먹거나 하는 주문 누락이 발생하지 않는다.
정리하자면
메시지를 많은 사용자에게 전달해야할 때
요청에 대한 처리시간이 길어 해당 요청을 다른 API에 위임하고 빠른 응답처리가 필요할 때
애플리케이션 간 결합도를 낮춰야 할 때
RabbitMQ를 사용한다
2. RabbitMQ는 어떻게 이루어져있는가?
[프로듀서 → 브로커(익스체인지+큐) → 컨슈머]
의 구조로 메시지를 전달해주는 메시징 서버
RabbitMQ는 다음과 같이 구성된다.
Producer: 메시지를 보내는 놈
Exchange: 메시지를 알맞은 큐에 전달해주는 놈
Queue: 메시지를 차곡차곡 쌓아두는 놈
Consumer: 메시지를 받는 놈
위 그럼처럼 Producer는 Queue에 직접 메시지를 전달하는 것이 아니다.
[프로듀서 → 익스체인지 → 큐 → 컨슈머]의 절차를 밟는다.
Exchange에서 알맞은 Queue로 메시지를 분배한다.(Exchange들과 Queue들은 바인딩되어있다)
무슨 기준으로 분배하느냐?
Exchange Type에 따라 다르다.
Exchange Type 4가지
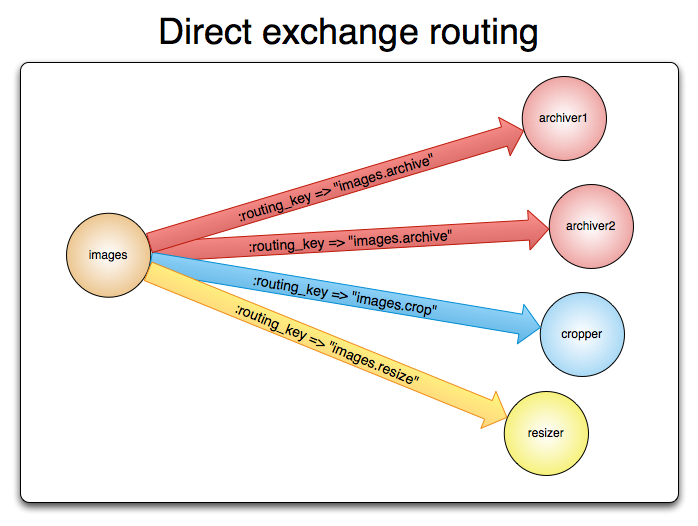
Direct
메시지에 포함된 Routing Key를 기반으로 특정 Queue에 메시지를 하나씩 전달한다.
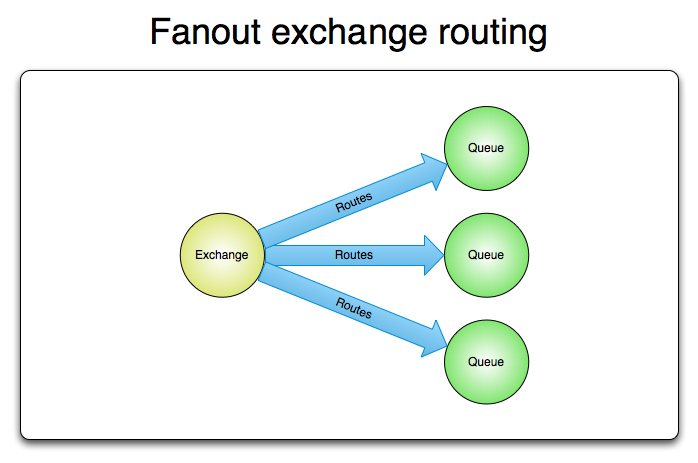
Fanout
Routing Key에 상관 없이 연결돼있는 모든 Queue에 동일한 메시지를 전달한다.
라우팅키를 평가할 필요가 없기때문에 성능적인 이점이 있다.
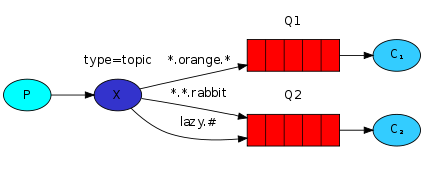
Topic
라우팅키 전체가 일치하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달된다.
Topic Exchange 에서 사용하는 binding key 는 점(.)으로 구분된 단어를 조합해서 정의한다.
* 와 #을 이용해 와일드 카드를 표현할 수 있으며, * 는 단어 하나 일치 # 는 0 또는 1개 이상의 단어 일치를 의미한다.
다음과 같이 binding key 를 정의한 경우에 메시지의 routing key 가 quick.orange.rabbit 또는 lazy.orange.elephant 이면, Q1, Q2 둘 다 전달된다. lazy.pink.rabbit 는 binding key 2개와 일치 하더라도 1번만 전달된다.
quick.brown.fox, quick.orange.male.rabbit 는 일치하는 binding key 가 없기 때문에 무시된다.
Header
메시지 속성 중 headers 테이블을 사용해 특정한 규칙의 라우팅을 처리한다.
x-match = any 일 경우 헤더 테이블 값 중 하나가 연결된 값 중 하나와 일치하면 메시지 전달
앞선 내용들을 통해 각각의 정의 및 프로세스에 대해 면밀히(?) 살펴봤다. 위 내용을 통해서도 kafka와 RabbitMQ의 차이에 대해 어느정도 이해할 수 있겠지만 본 글의 주제가 주제인만큼 다시 한번 간단히 정리해보도록 하겠다.
kafka는 pub/sub 방식 / RabbitMQ는 메시지 브로커 방식 kafka의 pub/sub방식은 생산자 중심적인 설계로 구성. 생성자가 원하는 각 메시지를 게시할 수 있도록 하는 메시지 배포 패턴으로 진행 RabbitMQ의메시지브로커방식은 브로커 중심적인 설계로 구성. 지정된 수신인에게 메시지를 확인, 라우팅, 저장 및 배달하는 역할을 수행하며 보장되는 메시지 전달에 초점
전달된 메시지에 대한 휘발성 RabbitMQ는 queue에 저장되어 있던 메시지에 대해 Event Consumer가져가게 되면 queue에서 해당 메시지를 삭제한다. 하지만, kafka는 생성자로부터 메시지가 들어오면 해당 메시지를 topic으로 분류하고 이를 event streamer에 저장한다. 그 후, 수신인이 특정 topic에 대한 메시지를 가져가더라도 event streamer는 해당 topic을 계속 유지하기 때문에 특정 상황이 발생하더라도 재생이 가능하다.
용도의 차이 kafka는 클러스터를 통해 병렬처리가 주요 차별점인 만큼 방대한 양의 데이터를 처리할 때, 장점이 부각된다. RabbitMQ는 데이터 처리보단 Manage UI를 제공하는 만큼 관리적인 측면이나, 다양한 기능 구현을 위한 서비스를 구축할 때, 장점이 부각된다.