반응형

Typeorm 문서에는 save() 메소드를 이렇게 설명한다
- 엔티티가 이미 존재하면 update
- 엔티티가 존재하지 않으면 insert
엔티티가 이미 존재하는지 어떻게 알까?
그렇다.
save() 메소드를 호출하면 select쿼리를 한번 실행시키고 그 뒤에 insert나 update 쿼리를 실행시킨다.
즉, 쿼리가 두번 나간다.

요런 코드를 돌려보자
[1]에서 콘텐츠 엔티티를 저장하고
[2]에서 저장한 엔티티를 조회하여 수정하고
[3]에서 수정한 엔티티를 다시 저장해보자
쿼리는 어떻게 발생할까?
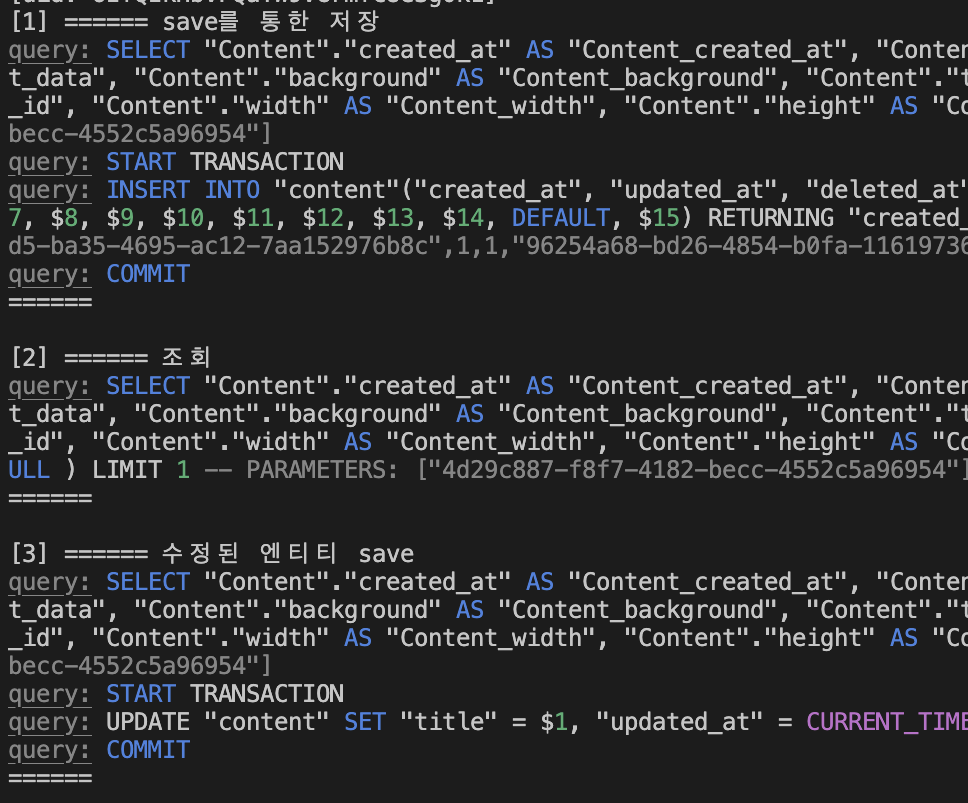
[1]에서는 기존에 없던 저장돼 있지 않던 엔티티이기에 select 쿼리 이후 insert쿼리가 발생한 것을 볼 수 있다.
[3]에서는 해당 엔티티의 pk기준으로 이미 존재하는 엔티티이기에 select 쿼리이후 update 쿼리가 발생한 것을 볼 수 있다.
근데 이제 select 쿼리는 계속 발생한다는 말인데 만약 저장하거나 수정해야 할 데이터가 많다면 각 쿼리마다 select 쿼리가 발생할텐데 상당히 비효율적이 아닐수가 없다.
직접 update() 메소드나 insert() 메소드를 사용하면 이런 문제를 개선할 수 있다.

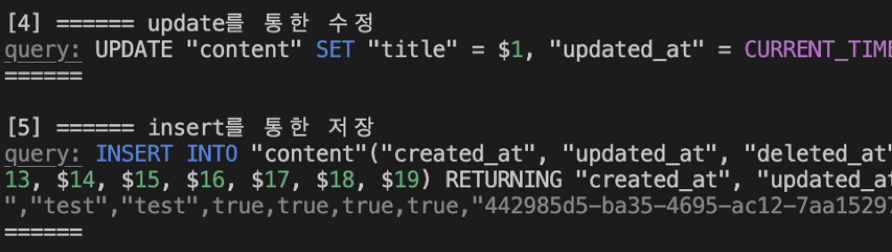
얌전하게 하나의 쿼리만 발생했다.
물론 save() 메소드가 주는 편리함을 포기하고 사용하는 것이므로 update나 insert를 할 때 디비에 중복되는 데이터가 이미 존재하는지 확인된 상태에서 사용하는것을 권한다. save()는 그냥 무지성으로 사용해도 pk가 겹치는게 아닌 이상 의도한대로 동작은 했는데 update(), insert()는 아니다.
반응형
'DB' 카테고리의 다른 글
| [Real MySQL] 인덱스 (1) | 2024.10.31 |
|---|---|
| [DB] 데이터베이스 정규화 (0) | 2021.07.14 |