1. JWT란?
Json Web Token의 줄임말이다.
두 개체에서 JSON객체를 사용하여 가볍고 자가수용적인 방식으로 정보를 안정성 있게 전달해 주는 인증 방식이다.
2. 세션과의 차이점
세션
보통 로그인을 구현할때 세션로그인을 많이 사용했다. 세션로그인이란,
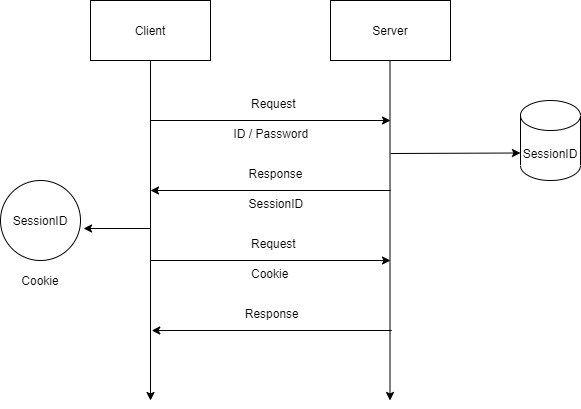
이런 흐름을 가지고 진행된다.
- 클라이언트에서 서버로 로그인 요청을 보낸다.
- 서버는 로그인 정보 확인 후 세션아이디를 응답한다. 이 세션아이디는 서버에서도 가지고있는다.
- 이후 클라이언트의 요청에는 2번에서 응답받은 세션아이디를 쿠키에 담아서 함께 요청한다.
- 서버는 함께 요청된 쿠키 속의 세션아이디를 확인하여 로그인된 사용자인지 확인한다.
이러한 세션 로그인 방식은 단점이 있다.
단점.
- 만약 여러대의 서버가 운영된다면, 서버측에서 저장하고있는 모든 세션을 공유해야한다.
- 사용자가 많아질수록 서버측에서 모든 사용자의 세션들을 저장하기 부담스럽다.
그러면 JWT는 이 문제를 어떻게 해결할까?
JWT
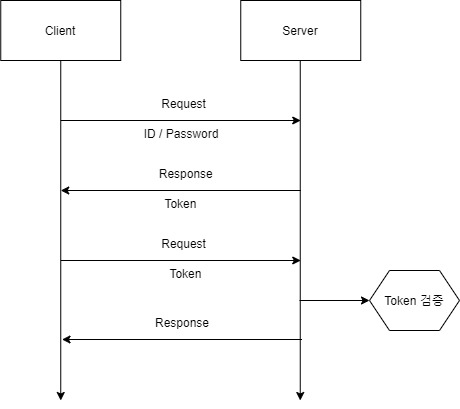
JWT방식은 다음과 같은 흐름을 가진다.
- 클라이언트에서 서버로 로그인 요청을 보낸다.
- 서버는 로그인 정보 확인 후 토큰을 응답한다. 이 토큰은 서버에서 보관하지 않는다.
- 이후 클라이언트의 2번에서 응답받은 토큰을 요청에 함께 보낸다.
- 서버는 토큰이 유효한지 검증하고 유효하면 로그인된 사용자라고 생각한다.
세션방식과 다른 가장 큰 포인트는, 로그인 후 무언가를 응답으로 보내주긴하는데 JWT는 서버측에서 그걸 기억하지 않는다는 것이다.
세션방식의 문제점 중 하나가 기억해야할 세션 아이디가 너무 많다는 것이었는데 이 문제점을 해결하는 부분이다.
서버는 자신이 발행한 토큰을 기억하지 않고, 나중에 토큰을 받으면 그 토큰이 유효한지 검증만 하면 되는 것이다.
또한 여러 디바이스나 도메인에서도 토큰에 대한 인증만 하면 되니 여러 서버가 운영될 때에도 문제 없다.
JWT가 마냥 좋은것만은 아니다.
세션은 시간에 따라 바뀌는 값을 갖는 stateful한 값이므로 어떠한 장점이 있느냐, 세션 값을 가지고있는 대상들을 제어할 수 있다. 예를 들어서 한 기기에서만 로그인이 가능하도록 구현하려 한다고 가정해보자.
1번 기기에 로그인이 돼있는데 2번 기기에서 로그인을 하면, 1번 기기의 세션을 종료하면 된다.
하지만 JWT는 사용자의 상태를 모르기 때문에 (stateless) 이것이 불가능하다. 이미 줘버린 토큰을 다시 회수할 수도 없고, 그 토큰의 발급 내용이나 정보를 서버가 추적하고 있지도 않기 때문이다. 반면 세션은 서버측의 세션저장소에 있기에 가능하다.
여담으로 지금 말한 단일 기기 로그인을 JWT로 해결하기 위한 기법도 존재한다.
- 최초 토큰 발행시 refresh 토큰과 access 토큰, 총 2개의 토큰을 발행한다.
- refresh토큰은 만료기한(수명)이 꽤 길고 access토큰은 매우 짧다.
- refresh토큰의 상응값을 데이터베이스에도 저장한다.
- 사용자가 요청할때 access토큰을 사용하는데 access토큰의 수명이 끝나면 refresh토큰을 사용해서 요청을 보낸다.
- 서버는 서버측의 refresh 토큰 상응값과 비교해보고 맞다면 새로운 access토큰을 발행해 준다.
- 즉, refresh토큰만 안전하게 관리된다면 중간에 access토큰이 탈취당해도 어자피 수명이 짧기 때문에 보안상 위협을 줄일 수 있고, 로그인 유지도 가능하다.
3. JWT의 구성
JWT토큰은 3개의 부분으로 구성된다.

실제로는
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
이렇게 생겼다. 각 부분을 디코딩해보면 JSON형태로 나온다.
헤더 (header)
헤더는 두가지 정보를 갖는다.
typ: 토큰의 타입을 지정. 여기는 JWT가 고정으로 들어간다. 여기가 JWT여야지만 JWT기 때문에
alg: 어떤 해싱 알고리즘을 사용할지 지정한다. 해싱 알고리즘으로는 보통 HMAC SHA256 혹은 RSA 가 사용되며, 이 알고리즘은, 토큰을 검증 할 때 사용되는 signature 부분에서 사용된다.
{
"typ": "JWT",
"alg": "HS256"
}
내용 (payload)
이 부분에는 토큰에 담을 정보가 들어있다. 이 정보의 한 조각을 "클레임(Claim)"이라고 부르고 key : value의 한 쌍으로 이루어져 있다. 클레임의 종류는 3가지로 분류된다.
등록된(registered) 클레임
등록된 클레임은 서비스에 필요한 정보가 아니라 토큰에 대한 정보를 담기위해 이름이 이미 정해진 클레임들이다. 등록된 클레임은 Optional하다.
- iss : 토큰 발급자 (issuer)
- sub : 토큰 제목 (subject)
- aud : 토큰 대상자 (audience)
- exp : 토큰의 만료시간 (expiraton), 시간은 NumericDate 형식으로 되어있어야 하며 (예: 1480849147370) 언제나 현재 시간보다 이후로 설정돼야한다.
- nbf : Not Before 를 의미하며, 토큰의 활성 날짜와 비슷한 개념. 여기에도 NumericDate 형식으로 날짜를 지정하며, 이 날짜가 지나기 전까지는 토큰이 처리되지 않는다.
- iat : 토큰이 발급된 시간 (issued at), 이 값을 사용하여 토큰의 age 가 얼마나 되었는지 판단 할 수 있다.
- jti : JWT의 고유 식별자로서, 주로 중복적인 처리를 방지하기 위하여 사용된다. 일회용 토큰에 사용하면 유용.
공개(public) 클레임
공개 클레임들은 충돌이 방지된 (collision-resistant) 이름을 가지고 있어야 한다. 충돌을 방지하기 위해서는, 클레임 이름을 URI 형식으로 짓는다.
{
"https://velopert.com/jwt_claims/is_admin": true
}비공개(private) 클레임
등록된 클레임도아니고, 공개된 클레임들도 아니다. 양 측간에 (보통 클라이언트 <->서버) 협의하에 사용되는 클레임 이름들이다. 공개 클레임과는 달리 이름이 중복되어 충돌이 될 수 있으니 사용할때에 유의.
{
"username": "velopert"
}
Payload의 예시
{
"iss": "llshl.com",
"exp": "1485270000000",
"https://llshl.com/jwt_claims/is_admin": true,
"userId": "11028373727102",
"username": "llshl"
}
서명 (signature)
서명은 헤더의 인코딩값과, 정보의 인코딩값을 합친후 주어진 비밀키로 해쉬를 하여 생성한다.
서버에서 요청에서 토큰을 받으면 헤더와 페이로드의 값을 서버의 비밀키와 함께 돌려서 계산된 결과값이 서명값과 일치하는지 확인한다.
한 줄 요약
"세션은 서버에서 세션아이디 보관,
JWT는 보관 없이 인증만"
참고:
'Web' 카테고리의 다른 글
| [Web] REST API (0) | 2021.07.03 |
|---|---|
| [Web] 세션과 쿠키 (0) | 2021.07.02 |