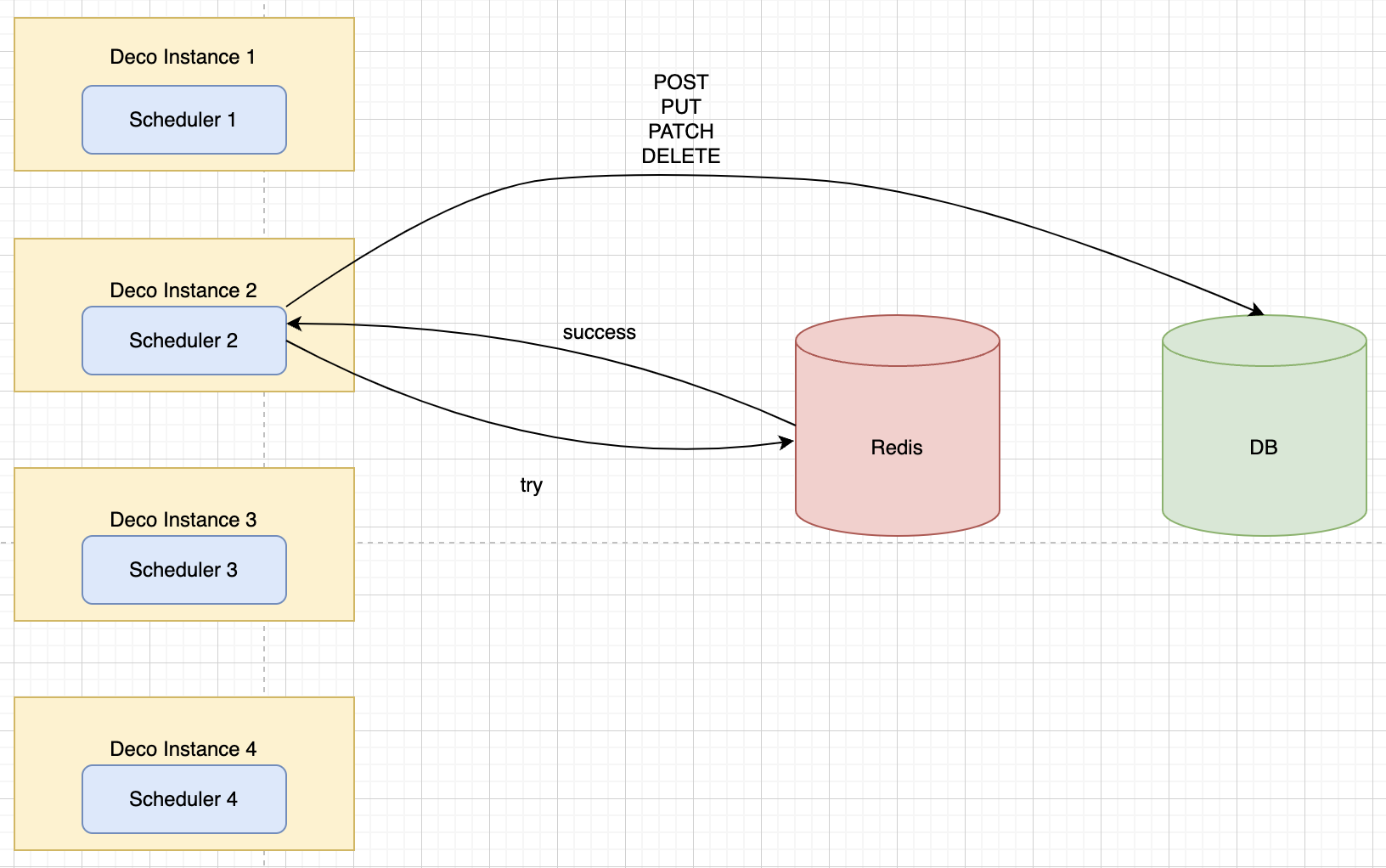
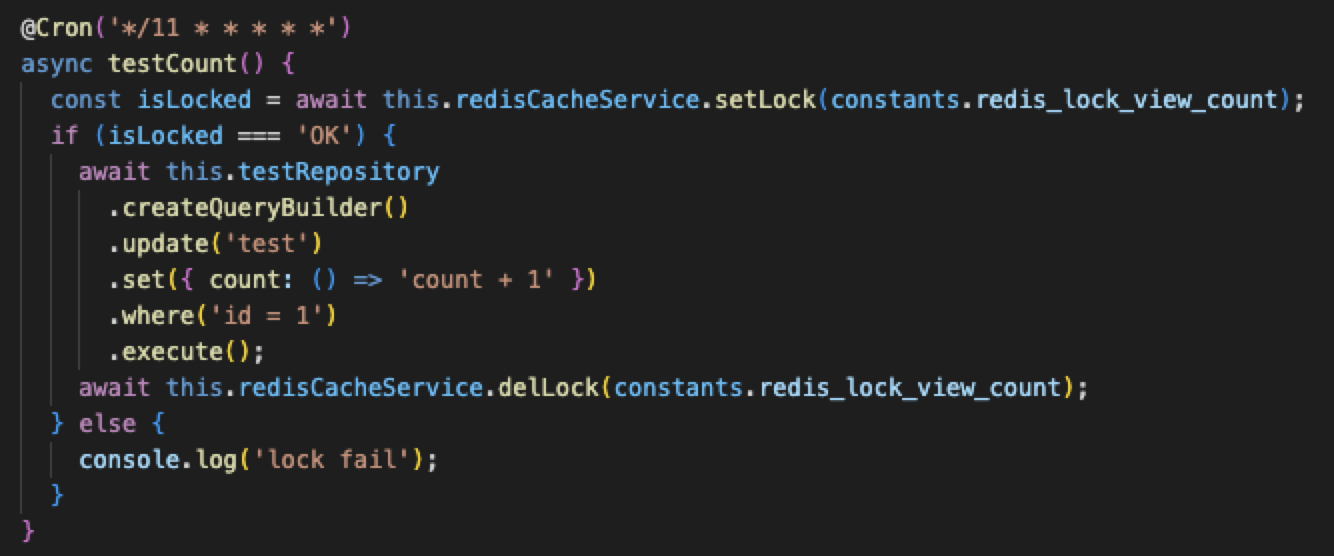
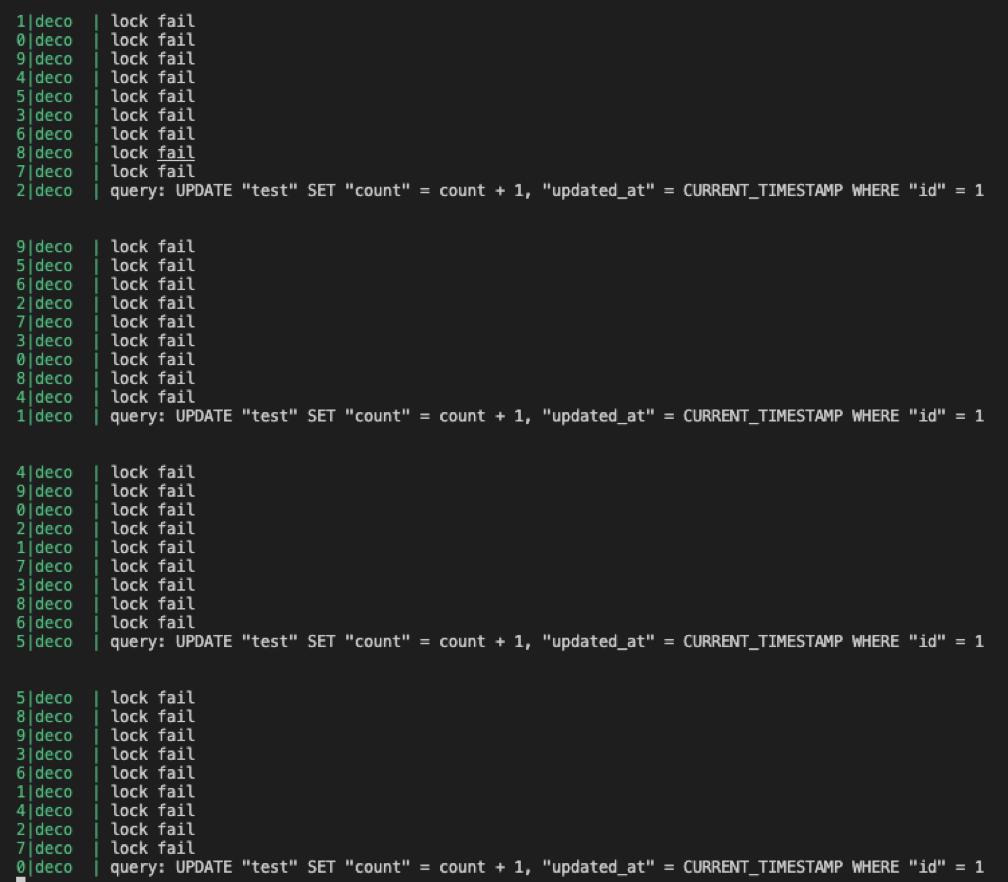
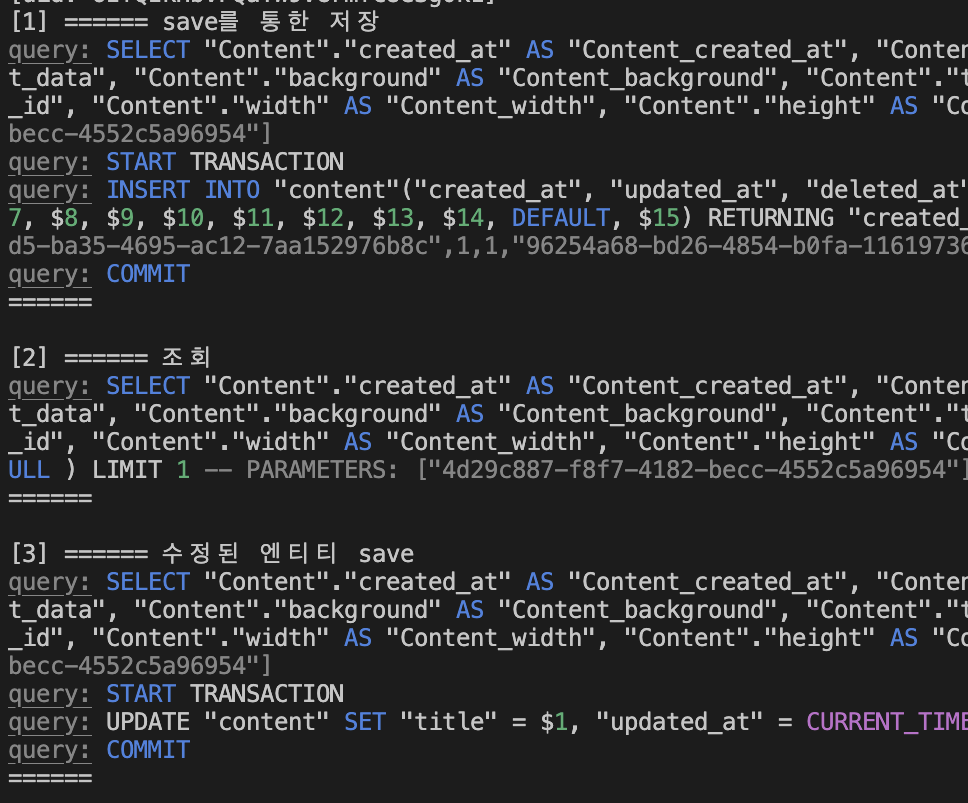
save() 메소드를 호출하면 select쿼리를 한번 실행시키고 그 뒤에 insert나 update 쿼리를 실행시킨다.
즉, 쿼리가 두번 나간다.
요런 코드를 돌려보자
[1]에서 콘텐츠 엔티티를 저장하고
[2]에서 저장한 엔티티를 조회하여 수정하고
[3]에서 수정한 엔티티를 다시 저장해보자
쿼리는 어떻게 발생할까?
[1]에서는 기존에 없던 저장돼 있지 않던 엔티티이기에 select 쿼리 이후 insert쿼리가 발생한 것을 볼 수 있다.
[3]에서는 해당 엔티티의 pk기준으로 이미 존재하는 엔티티이기에 select 쿼리이후 update 쿼리가 발생한 것을 볼 수 있다.
근데 이제 select 쿼리는 계속 발생한다는 말인데 만약 저장하거나 수정해야 할 데이터가 많다면 각 쿼리마다 select 쿼리가 발생할텐데 상당히 비효율적이 아닐수가 없다.
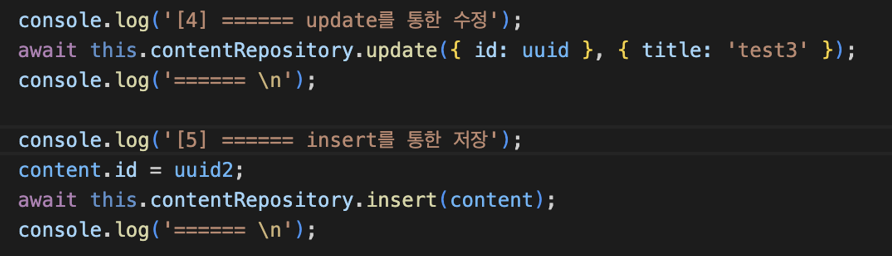
직접 update() 메소드나 insert() 메소드를 사용하면 이런 문제를 개선할 수 있다.
얌전하게 하나의 쿼리만 발생했다.
물론 save() 메소드가 주는 편리함을 포기하고 사용하는 것이므로 update나 insert를 할 때 디비에 중복되는 데이터가 이미 존재하는지 확인된 상태에서 사용하는것을 권한다. save()는 그냥 무지성으로 사용해도 pk가 겹치는게 아닌 이상 의도한대로 동작은 했는데 update(), insert()는 아니다.
토큰이란 몇몇 공통 규약을 따르는 스마트 컨트랙트다. 공통 함수집합이 있다. transfer()나 balanceOf()같은
ERC20토큰들이 똑같은 함수 집합을 공유하기에 이 토큰들은 똑같은 방식으로 상호작용 가능하다
내가 ERC20 토큰과 상호작용하는 앱을 만들면 모든 ERC20 토큰과 상호작용이 된다.
이것의 한가지 예시로는 거래소가 있다.
ERC20 토큰을 상장할때 실제로는 거래소에서 통신 가능한 또 하나의 스마트 컨트랙을 추가하는 것이다.
ERC20은 교체 가능
ERC721은 교체 불가능
contract SatoshiNakamoto is NickSzabo, HalFinney {
// 이렇게 다중 상속 가능
}
전송
ERC721 스펙에서는 토큰을 전송할 때 2개의 다른 방식이 있다.
function transfer(address _to, uint256 _tokenId) public;
function approve(address _to, uint256 _tokenId) public;
function takeOwnership(uint256 _tokenId) public;
첫 번째 방법은 토큰의 소유자가 전송 상대의address, 전송하고자 하는_tokenId와 함께transfer함수를 호출하는 것.
두 번째 방법은 토큰의 소유자가 먼저 위에서 본 정보들을 가지고approve를 호출하는 것. 그리고서 컨트랙트에 누가 해당 토큰을 가질 수 있도록 허가를 받았는지 저장한다. 보통mapping (uint256 => address)를 쓴다. 이후 누군가takeOwnership을 호출하면, 해당 컨트랙트는 이msg.sender가 소유자로부터 토큰을 받을 수 있게 허가를 받았는지 확인한다. 그리고 허가를 받았다면 해당 토큰을 그에게 전송한다.
transfer와takeOwnership모두 동일한 전송 로직을 가지고 있다.
순서만 반대인 것(전자는 토큰을 보내는 사람이 함수를 호출하고, 후자는 토큰을 받는 사람이 호출하는 것).
safeMath
function add(uint256 a, uint256 b) internal pure returns (uint256) {
uint256 c = a + b;
assert(c >= a);
return c;
}
assert는 조건을 만족하지 않으면 에러를 발생시킨다는 점에서require와 비슷하다.assert와require의 차이점은,require는 함수 실행이 실패하면 남은 가스를 사용자에게 되돌려 주지만,assert는 그렇지 않다는 것이다.assert는 일반적으로 코드가 심각하게 잘못 실행될 때 사용하네(like, uint오버플로우의 경우)
일반적인 웹 서버에서 API 함수를 실행할 때에는, 우리는 함수 호출을 통해서 US 달러를 보낼 수 없다. 물론 비트코인도.
하지만 이더리움에서는, 돈(이더), 데이터(transaction payload), 그리고 컨트랙트 코드 자체 모두 이더리움 위에 존재하기 때문에, 우리가 함수를 실행하는동시에컨트랙트에 돈을 지불하는 것이 가능하다.
contract OnlineStore {
function buySomething() external payable {
// 함수 실행에 0.001이더가 보내졌는지 확실히 하기 위해 확인:
require(msg.value == 0.001 ether);
// 보내졌다면, 함수를 호출한 자에게 디지털 아이템을 전달하기 위한 내용 구성:
transferThing(msg.sender);
}
}
여기서, msg.value는 컨트랙트로 이더가 얼마나 보내졌는지 확인하는 방법.
컨트랙트에서 이더를 꺼내는 방법
contract GetPaid is Ownable {
function withdraw() external onlyOwner {
owner.transfer(this.balance);
}
}
this.balance는 컨트랙트에 저장돼있는 전체 잔액을 반환
한 가지 활용법으로는 구매자와 판매자가 존재하는 컨트랙트에서, 판매자의 주소를 storage에 저장하고, 누군가 판매자의 아이템을 구매하면 구매자로부터 받은 요금을 그에게 전달할 수도 있다
seller.transfer(msg.value)
난수
keccak256을 통해 난수를 만들수있지만 이 방법은 정직하지 않은 노드의 공격에 취약하다.
우리가 이더리움에서 컨트랙트의 함수를 실행하게되면 이를 하나의 트랜잭션(transaction)으로서 네트워크의 노드 하나 혹은 여러 노드에 실행을 알리게 된다. 그 후 네트워크의 노드들은 여러 개의 트랜잭션을 모으고, "작업 증명"으로 알려진 계산이 매우 복잡한 수학적 문제를 먼저 풀기 위한 시도를 하게 된다. 그리고서 해당 트랜잭션 그룹을 그들의 작업 증명(PoW)과 함께블록으로 네트워크에 배포하게 된다.
이것이 우리의 난수 함수를 취약하게 만든다
내가 만약 노드를 실행하고 있다면, 나는 오직 나의 노드에만 트랜잭션을 알리고 이것을 공유하지 않을 수 있다.
우리가 동전 던지기 컨트랙트를 사용한다고 할 때 해보자. 내가 동전을 던져서 당첨이 되지 않았다면 내가 풀고 있는 다음 블록에 해당 트랜잭션을 포함하지 않을 수 있다. 당첨이 된 경우에만 선택적으로 트랜잭션을 다음 블록에 추가시키면 된다.
이 짓을 무한대로 반복할 수 있기에 문제.
개선하는 방법은 oracle(이더리움 외부에서 데이터를 받아오는 안전한 방법 중 하나)을 사용해서 블록체인 밖에서 안전한 난수를 만드는 방법
특정한 함수들에 대해서 오직소유자만 접근할 수 있도록 제한 가능한onlyOwner제어자를 추가한다.
새로운소유자에게 해당 컨트랙트의 소유권을 옮길 수 있도록 한다.
의 역할을 수행할 수 있다. (일단 여기서 사용하는것들은 이렇다)
함수 제어자
함수 제어자는 함수처럼 보이지만,function키워드 대신modifier키워드를 사용.
함수를 호출하듯이 직접 호출할 수는 없다.
함수 정의부 끝에 해당 함수의 작동 방식을 바꾸도록 제어자의 이름을 붙일 수 있다.
/**
* @dev Throws if called by any account other than the owner.
*/
modifier onlyOwner() {
require(msg.sender == owner);
_;
}
이렇게 생김
contract MyContract is Ownable {
event LaughManiacally(string laughter);
// 아래 `onlyOwner`의 사용 방법을 잘 보게:
function likeABoss() external onlyOwner {
LaughManiacally("Muahahahaha");
}
}
likeABoss함수를 호출하면,onlyOwner의 코드가먼저실행된다. 그리고onlyOwner의_;부분을likeABoss함수로 되돌아가 해당 코드를 실행하게 된다.
제어자를 사용할 수 있는 다양한 방법이 있지만, 가장 일반적으로 쓰는 예시 중 하나는 함수 실행 전에require체크를 넣는 것.
onlyOwner의 경우에는, 함수에 이 제어자를 추가하면오직컨트랙트의소유자(배포한 사람)만이 해당 함수를 호출할 수 있다.
--> 사용자들이 우리 컨트랙트를 마구 수정하지 못하게 하면서도 우리 디앱의 핵심적인 부분을 업데이트할 수 있도록 하는 방법이다
가스
솔리디티에서 사용자들은 함수를 호출할때마다 가스를 사용한다
솔리디티에서는uint의 크기에 상관없이 256비트의 저장 공간을 미리 잡아놓기 때문에 하위 타입들을 쓰는 것은 아무런 이득이 없다.
예를들어,uint(uint256) 대신에uint8을 쓰는 것은 가스 소모를 줄이는 데에 아무 영향이 없다.
하지만 struct 안에서는 다르다.
만약 구조체 안에 여러 개의uint를 만든다면, 가능한 더 작은 크기의uint를 쓰는게 좋다.
struct NormalStruct {
uint a;
uint b;
uint c;
}
struct MiniMe {
uint32 a;
uint32 b;
uint c;
}
// `mini`는 구조체 압축을 했기 때문에 `normal`보다 가스를 조금 사용할 것이네.
NormalStruct normal = NormalStruct(10, 20, 30);
MiniMe mini = MiniMe(10, 20, 30);
인수를 가지는 함수 제어자
함수 제어자는 사실 인수 또한 받을 수 있다.
// 사용자의 나이를 저장하기 위한 매핑
mapping (uint => uint) public age;
// 사용자가 특정 나이 이상인지 확인하는 제어자
modifier olderThan(uint _age, uint _userId) {
require (age[_userId] >= _age);
_;
}
// 차를 운전하기 위햐서는 16살 이상이어야 하네(적어도 미국에서는).
// `olderThan` 제어자를 인수와 함께 호출하려면 이렇게 하면 되네:
function driveCar(uint _userId) public olderThan(16, _userId) {
// 필요한 함수 내용들
}
olderthan제어자가 함수와 비슷하게 인수를 받는 것을 볼 수 있다. 그리고driveCar함수는 받은 인수를 제어자로 전달하고 있다.
View 함수는 가스를 소모하지 않는다
view함수는 사용자에 의해 외부에서 호출되었을 때 가스를 전혀 소모하지 않는다.
이건view함수가 블록체인 상에서 실제로 어떤 것도 수정하지 않기 때문 - 데이터를 읽기만 하지.
함수에view표시를 하는 것은
"이 함수는 실행할 때 자네 로컬 이더리움 노드에 질의만 날리면 되고, 블록체인에 어떤 트랜잭션도 만들지 않아"
라고 web3.js에 이렇게 말하는 것과 같다.
(트랜잭션은 모든 개별 노드에서 실행되어야 하고, 가스를 소모한다).
참고: 만약 view 함수가 동일 컨트랙트 내에 있는, view 함수가 아닌 다른 함수에서 내부적으로 호출될 경우, 여전히 가스를 소모할 것이다. 이것은 다른 함수가 이더리움에 트랜잭션을 생성하고, 이는 모든 개별 노드에서 검증되어야 하기 때문.
그러니 view 함수는 외부에서 호출됐을 때에만 무료다.
(pure는 블록체인으로부터 어떤 데이터도 읽거나 쓰지 않는다는 뜻)
storage
솔리디티에서 storage는 비싸다
storage 대신 함수가 종료될때 사라지는 memory를 사용하는것도 하나의 방법
function getArray() external pure returns(uint[]) {
// 메모리에 길이 3의 새로운 배열을 생성한다.
uint[] memory values = new uint[](3);
// 여기에 특정한 값들을 넣는다.
values.push(1);
values.push(2);
values.push(3);
// 해당 배열을 반환한다.
return values;
}