이 카테고리는 Ground X에서 진행한 한양대학교 일반대학원 블록체인 융합학과 강의와 그 외의 참고자료를 보고 정리하는 곳입니다. 강의 동영상은 여기서 볼 수 있습니다.
너무 빈약한 지식이기에 이 글을 신뢰하지는 마세요.. 혹시 지나가시다가 잘못된 점 발견하시면 피드백 부탁드립니다.
1. 블록체인이란?
- 블록은 정보다.
- 정보를 블록이라고 하는 단위로 저장하고 이 블록들을 이어붙혀서 체인 형태로 저장하는 기술.
- 블록은 더하기만 가능하고 수정과 삭제가 힘들다.
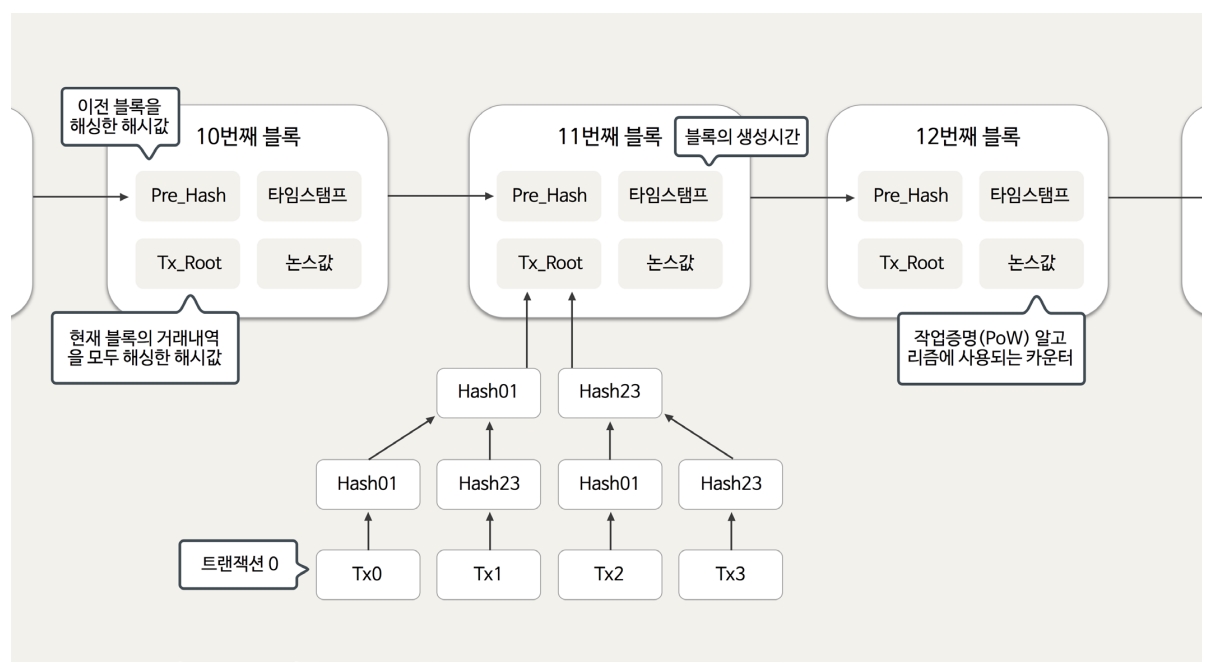
- 블록은 [내 블록의 해시값], [이전 블록의 해시값], [내 데이터]로 구성된다.
- 조금더 자세히 말해보면, 블록체인은 데이터 분산 처리 기술이다.
- 블록은 개인과 개인의 거래 장부의 역할을 하고, 이를 조작하려면 모든 사람의 장부를 조작해야한다.
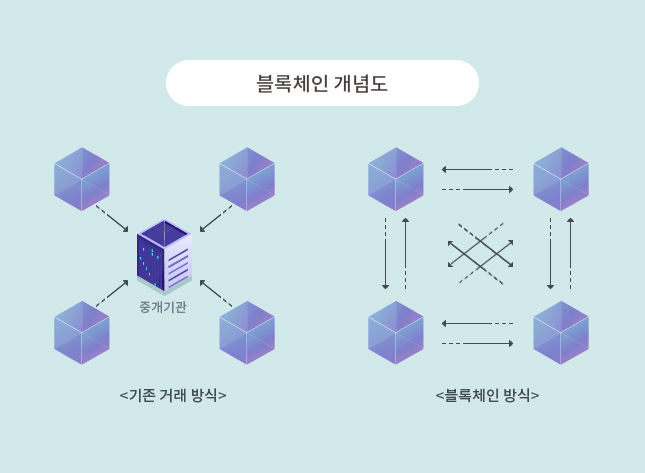
기존 거래 방식
은행이 모든 거래 내역을 가지고있다. A가 B에게 10만원을 송금한다고 하면 은행이 중간역할을 한다.
A가 B에게 10만원을 보냈다는 사실을 증명해줘야 하기 때문이다.
우리는 오직 은행만을 신뢰하게 된다. 증명해 줄 곳이 은행뿐이니까. 그렇기에 이 은행에 문제가 생기면 A는 돈을 보냈다는 사실을 증명할 수 없고 결국 돈을 잃는다.
블록체인 방식
블록체인도 거래 내역을 저장하고 증명한다. 단, 은행처럼 한 곳이 전담하는게 아닌 여러명이 나눠서 맡는다.
한 네트워크에 10명의 참여자가 있다면 A가 B에게 10만원을 보낸 내역을 10개의 블록으로 생성해 10명 모두에게 전송, 저장한다. 나중에 거래내역을 확인할 때는 블록으로 저장한 데이터들을 연결해 확인한다.
보안이 탄탄한 한 명이 모든 장부를 관리하는 것이 아닌 모두가 장부를 관리한다. 그렇기에 장부를 조작하려면 한 개만 조작해선 될게 아니다.
2. 블록체인의 활용
화폐(Currencies)
- 이체와 화폐의 기능을 수행하는 전자 화폐.
- 규제, 감독, 법제화 등 관련된 공인성은 없음
- 예) 비트코인, 라이트코인, 다크코인, 피어코인, 도기코인 등
자산 등록(Asset Registry)
- 자산 등록을 블록체인에 기록 하고, 개인키로 자산의 소유권을 주장하는 장부 기능.
- 블록의 크기가 화폐용 블록보다 상대적으로 크며, 네트워크 성능 저하와 고비용 수반함.
- 예) 컬러드코인, 옴니, 카운터파티 등
응용 플랫폼(Application Platform)
- 네트웍상에 존재하는 블록체인에 응용프로그램을 개발하고 작동시키는 플랫폼 역할
- 아직까지 서비스 초기이기 때문에 취약점이 다수 존재
- 예) 이더리움, 에리스, NXT 등
자산 중심(Assent Centric)
- 화폐, 자원. 주식, 채권의 거래를 일부 사용자만 볼 수 있는 공유장부에 기술함. (비트코인은 공개된 장부)
- 외환 거래, 송금, 결제, 이체를 목적으로 두고 있음.
- 예)리플, 스텔라
3. 해시함수
해시는 전에도 정리했던 적이 있다.
https://llshl.tistory.com/17?category=942551
[Java] 해시/해시테이블이란?
사실 자료구조 카테고리에 맞는 게시글이지만 아직 자료구조 카테고리가 없고 앞으로 딱히 만들 계획이 없기에, 그리고 구현을 자바로 했기에 자바 카테고리에 넣었다! 그냥 그런걸로 하자 ㅎ
llshl.tistory.com
- 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수,
- 한 개의 인풋은 한 개의 아웃풋만을 가진다.
- 조금만 인풋이 달라도 아웃풋은 크게 바뀐다.
- 블록체인에는 Keccak256을 많이 쓴다 카더라(아직 잘 모름)
- [이전 블록의 해시값]을 통해서 이전 블록을 포인팅하기에 블록의 순서를 알 수 있다.
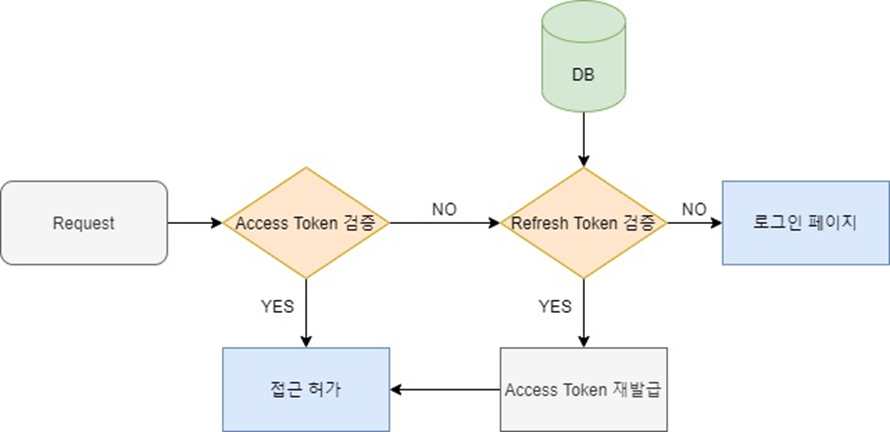
4. 블록 생성 과정
블록 생성 시간 == 거래 소요 시간
- 블록체인상에서의 장부 작성은 블록체인 네트워크에 참여하고 있는 사람들(이를 노드라고 한다)이 그 기록이 참인지 거짓인지 과반수의 동의를 얻어야 장부에 기록이 된다.
- 이 노드들은 전 세계적으로 분산되어있고 전세계를 아우르는 하나의 거대한 장부를 형성한다. 따라서 신뢰가 필요가 없이 합의를 통해서 기록이 작성된다.
- 가장 많고 가장 빨리 작업을 한 사람이 블록에 기록하고 블록을 생성할 수 있는 투표권을 더 많이 갖는다고 할 수 있다. (작업증명)
- 합의 알고리즘은 여러 방법이 있고 3개만 알아보자.
5. 합의 알고리즘
합의 알고리즘이란,
- P2P 네트워크에서 정보의 지연과 미 도달을 통해 잘못된 정보 or 정보의 중복이 발생할 수 있다.
- 이때 어떤 블록이 정당한지 검토하고 체인에 연결하기 위해 참가자들의 함의를 얻기 위한 알고리즘이다.
PoW
- Proof Of Work, 비트코인, 비트코인 캐시, 라이트코인 등이 있다.
- 누구나 참여 가능.
- 풀기 어려운 문제를 빨리 해결한 사람에게 블록을 생성할 수 있는 권한을 주고 그 보상으로 코인을 제공하는 알고리즘
- [앞 블록의 해시] + [Nonce] = [어떤 해시 값]을 만족하는 Nonce를 찾는 문제이다.
- 난이도라는게 존재하는데 난이도가 4라면 어떤 해시 값은 4개의 0으로 시작하는 값이어야 한다.
- 즉, Nonce를 빠르게 돌리면서 4개의 0으로 시작하는 해시값이 나오면 Nonce를 찾았다고 할 수 있다.
- 연산량의 51퍼센트를 한 명의 참여자가 소유하면 블록을 조작할 수 있다.
- Nonce를 찾기 위해 전기를 너무 많이 써야한다.
PoS
- Proof Of Stake, 대시, 네오 등이 있다.
- 자신이 네트워크에 얼마만큼의 지분을 가지고 있는지로 판단. 즉 가지고있는 재산에 비례
- 지분을 많이 가지고 있으면 높은 확률로 다음 블록을 제안할 수 있다.
- 중앙 집중화를 예방하고 PoW보다 에너지를 절약한다.
- 코인을 독식한 사람이 너무 강한 권력을 지니게 된다.
- 그렇기에 PoW와 연계하여 사용한다고 한다.
BFT
- PoW와 PoS의 단점인 *파이널리티의 불확실성을 해결한 것
- 정해진 순번에 따라서 다음 블록을 누가 제안할지 정함
- 네트워크가 동기화 되어있다. 즉 네트워크 참여자가 누구인지 다 알고있기에 새로운 참여자가 들어가면 작업을 멈추고 동기화를 진행해야한다.
- 좀 느림
* 블록체인이 분기하게 되는 경우 긴 체인이 올바른 것으로 판단한다. 짧은 체인이 버려지는 경우 트랜잭션이 없었던 일이 될 수 있다.
6. Public vs Private
- 누구든지 기록된 정보를 자유롭게 읽을 수 있는가?
- 명시적인 등록 또는 자격 취득 없이도 블록체인 네트워크에 기록할 수 있는가?
라는 질문에 예라고 답하면 Public/공개형 블록체인이라고 한다.
반대로 정보가 공개돼 있지 않고 미리 자격을 얻은 사람만이 정보를 기록할 수 있다면 Private/비공개형 블록체인이라고 한다.
퍼블릭 블록체인은 누구나 접근 가능하고 익명이다.
프라이빗 블록체인은 정보를 비밀로 공유하고 아무나 못들어온다. 또 익명이 아니다.(기업 특화)
참고:
블록체인 합의 알고리즘 알아보기 1편(PoW, PoS, DPoS)
안녕하십니까 블록체인 알려주는 남자 Ryan KIM 입니다.
medium.com
https://medium.com/b-ock-chain/pow-%EC%99%80-pos-%EC%9D%98-%EC%A0%95%EC%9D%98-962a36d0979
PoW 와 PoS 의 정의
안녕하세요 이번에 PoW 와 PoS에 대한 포스팅을 맡게된 Seonmi입니다 :) 앞으로 잘부탁드릴게요!
medium.com
다 아는 것 같은데 은근 잘 모르는 블록체인의 개념 - 마크애니
다 아는 것 같은데 은근 잘 모르는 블록체인의 개념 ‘블록체인’하면 어떤 게 떠오르세요? 많은 분들이 ‘코인’, 가상화폐를 제일먼저 떠올리실 것 같습니다. 재작년 소위 비트코인광풍으로
www.markany.com
[신기술]블록체인 이란? - 블록체인 개념 이해하기(퍼블릭,프라이빗,컨소시엄,하이브리드)
블록체인은 무엇일까요? 블록체인 이란? 블록체인은 데이터 분산 처리 기술이다. 즉, 네트워크에 참여하는 모든 사용자가 모든 거래 내역 등의 데이터를 분산, 저장하는 기술을 지칭하는 말이다
wooaoe.tistory.com
https://www.youtube.com/playlist?list=PLKqrwxupttYEcJhWAw0E_5RVpDD9LD6Q-
Klaytn 클레이튼 스마트계약과 탈중앙앱 강의
이 수업은 한양대학교 일반대학원(석사과정) 블록체인 융합학과에서 한 학기동안 진행하게 된 블록체인 플랫폼 클레이튼을 활용한 스마트계약과 탈중앙앱 개발에 대한 수업입니다. 이 강의를
www.youtube.com
'Block Chain' 카테고리의 다른 글
| [블록체인] 블록체인 노드란? (1) | 2021.11.24 |
|---|---|
| [블록체인] 블록체인의 활용 (0) | 2021.08.29 |
| [블록체인] 블록체인 애플리케이션 BApp (1) | 2021.08.28 |
| [블록체인] 스마트 컨트랙트 (0) | 2021.08.26 |
| [블록체인] 트랜잭션과 가스비 (0) | 2021.08.24 |