RabbitMQ는 데이터를 잠시 보관하고 나중에 비동기적으로 처리하고 싶을 경우 사용하는 일종의 데이터 저장소이다.
*AMQP:Advanced Message Queing Protocol의 약자로, 흔히 알고 있는 MQ의 오픈소스에 기반한 표준 프로토콜
실생활에서 예를 들어보자
스타벅스에서 손님들이 줄을 서서 커피를 주문한다.
1. 메시지 큐X
첫번째 손님이 커피를 주문하면 첫번째 손님의 커피가 완성될때까지 두번째 손님은 계속 줄을 서서 대기해야한다.
2. 메시지 큐O
첫번째 손님은 커피를 주문하고 자리로 간다. 두번째, 세번째 손님들도 주문서만 던져놓고 자리로 간다. 바리스타는 쌓여가는 주문서들을 보며 순서대로 커피를 만든다. 커피가 만들어지면 손님들이 받아간다.
이때 손님(프로듀서)들이 바리스타(컨슈머)에게 던져놓는 주문서가 메시지가 되고 주문서가 쌓여가는 곳이 메시지 큐가 된다.
이런 구조는 커피를 비동기적으로 만들기에 효율적이며,
주문서는 바리스타에게 전달될때 까지 잠시 저장되기에 바리스타가 까먹거나 하는 주문 누락이 발생하지 않는다.
정리하자면
메시지를 많은 사용자에게 전달해야할 때
요청에 대한 처리시간이 길어 해당 요청을 다른 API에 위임하고 빠른 응답처리가 필요할 때
애플리케이션 간 결합도를 낮춰야 할 때
RabbitMQ를 사용한다
2. RabbitMQ는 어떻게 이루어져있는가?
[프로듀서 → 브로커(익스체인지+큐) → 컨슈머]
의 구조로 메시지를 전달해주는 메시징 서버
RabbitMQ는 다음과 같이 구성된다.
Producer: 메시지를 보내는 놈
Exchange: 메시지를 알맞은 큐에 전달해주는 놈
Queue: 메시지를 차곡차곡 쌓아두는 놈
Consumer: 메시지를 받는 놈
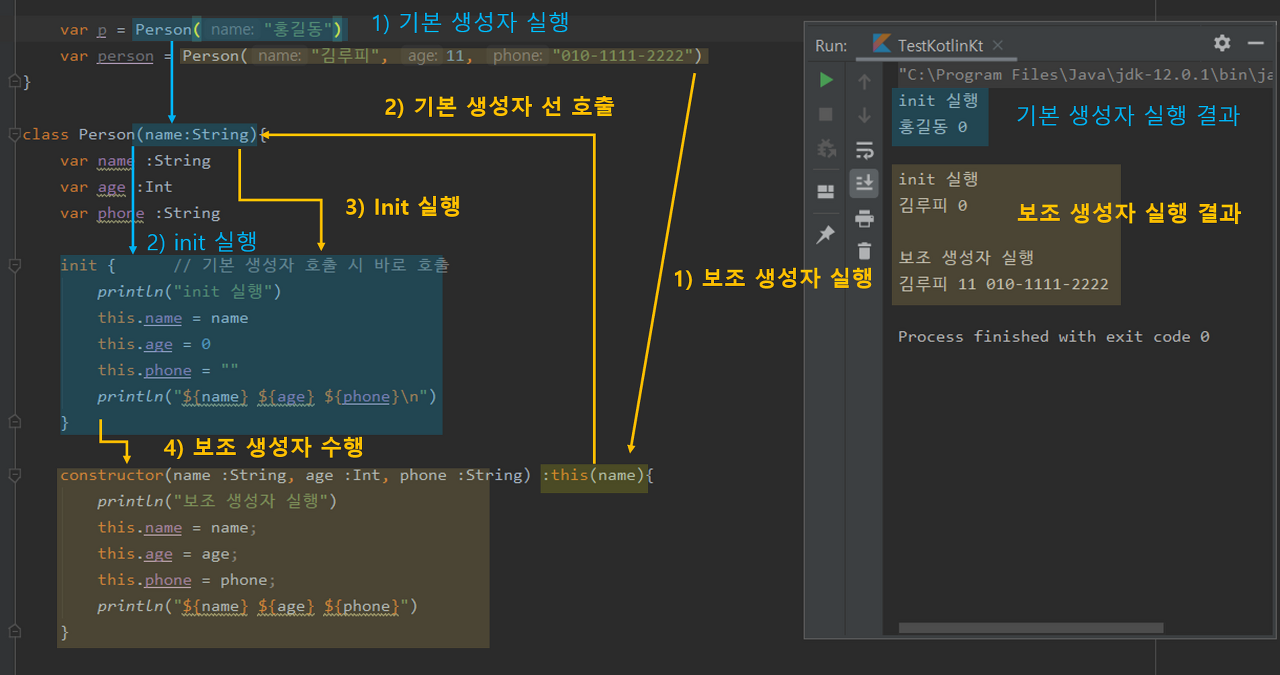
위 그럼처럼 Producer는 Queue에 직접 메시지를 전달하는 것이 아니다.
[프로듀서 → 익스체인지 → 큐 → 컨슈머]의 절차를 밟는다.
Exchange에서 알맞은 Queue로 메시지를 분배한다.(Exchange들과 Queue들은 바인딩되어있다)
무슨 기준으로 분배하느냐?
Exchange Type에 따라 다르다.
Exchange Type 4가지
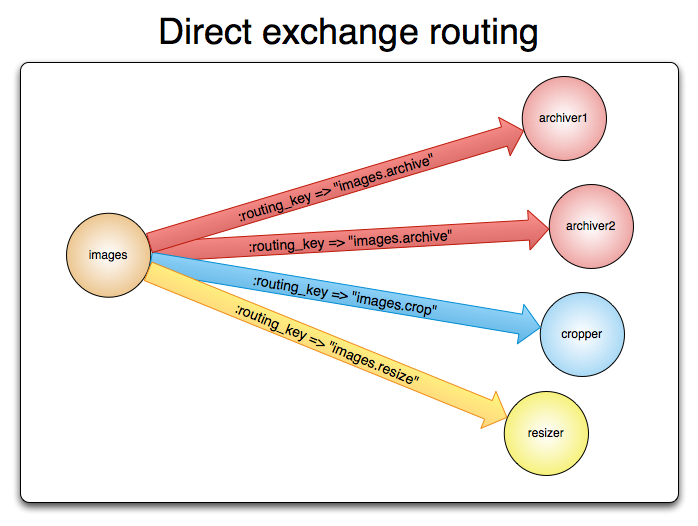
Direct
메시지에 포함된 Routing Key를 기반으로 특정 Queue에 메시지를 하나씩 전달한다.
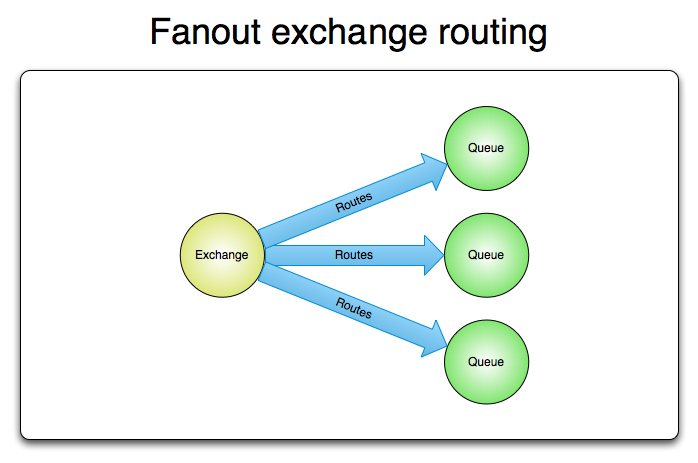
Fanout
Routing Key에 상관 없이 연결돼있는 모든 Queue에 동일한 메시지를 전달한다.
라우팅키를 평가할 필요가 없기때문에 성능적인 이점이 있다.
Topic
라우팅키 전체가 일치하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달된다.
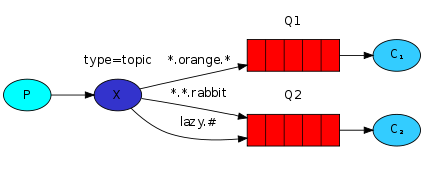
Topic Exchange 에서 사용하는 binding key 는 점(.)으로 구분된 단어를 조합해서 정의한다.
* 와 #을 이용해 와일드 카드를 표현할 수 있으며, * 는 단어 하나 일치 # 는 0 또는 1개 이상의 단어 일치를 의미한다.
다음과 같이 binding key 를 정의한 경우에 메시지의 routing key 가 quick.orange.rabbit 또는 lazy.orange.elephant 이면, Q1, Q2 둘 다 전달된다. lazy.pink.rabbit 는 binding key 2개와 일치 하더라도 1번만 전달된다.
quick.brown.fox, quick.orange.male.rabbit 는 일치하는 binding key 가 없기 때문에 무시된다.
Header
메시지 속성 중 headers 테이블을 사용해 특정한 규칙의 라우팅을 처리한다.
x-match = any 일 경우 헤더 테이블 값 중 하나가 연결된 값 중 하나와 일치하면 메시지 전달
앞선 내용들을 통해 각각의 정의 및 프로세스에 대해 면밀히(?) 살펴봤다. 위 내용을 통해서도 kafka와 RabbitMQ의 차이에 대해 어느정도 이해할 수 있겠지만 본 글의 주제가 주제인만큼 다시 한번 간단히 정리해보도록 하겠다.
kafka는 pub/sub 방식 / RabbitMQ는 메시지 브로커 방식 kafka의 pub/sub방식은 생산자 중심적인 설계로 구성. 생성자가 원하는 각 메시지를 게시할 수 있도록 하는 메시지 배포 패턴으로 진행 RabbitMQ의메시지브로커방식은 브로커 중심적인 설계로 구성. 지정된 수신인에게 메시지를 확인, 라우팅, 저장 및 배달하는 역할을 수행하며 보장되는 메시지 전달에 초점
전달된 메시지에 대한 휘발성 RabbitMQ는 queue에 저장되어 있던 메시지에 대해 Event Consumer가져가게 되면 queue에서 해당 메시지를 삭제한다. 하지만, kafka는 생성자로부터 메시지가 들어오면 해당 메시지를 topic으로 분류하고 이를 event streamer에 저장한다. 그 후, 수신인이 특정 topic에 대한 메시지를 가져가더라도 event streamer는 해당 topic을 계속 유지하기 때문에 특정 상황이 발생하더라도 재생이 가능하다.
용도의 차이 kafka는 클러스터를 통해 병렬처리가 주요 차별점인 만큼 방대한 양의 데이터를 처리할 때, 장점이 부각된다. RabbitMQ는 데이터 처리보단 Manage UI를 제공하는 만큼 관리적인 측면이나, 다양한 기능 구현을 위한 서비스를 구축할 때, 장점이 부각된다.
처음 언어를 배울때 일단 부딪혀가며 습득하자는 생각이라 주먹구구식으로 일단은 개발했던것 같다.
그 과정에서 정리가 필요한 부분들을 느꼈고 간단하게나마 적어보려한다.
1. 기본생성자
코틀린 클래스는 다음과 같이 생성한다.
classTestClass{
}
이 클래스는 생성자도 프로퍼티(얘도 상당히 중요한 개념인것 같다. 다음 글에서 정리해봐야겠다)도 없는 클래스다
여기에 기본생성자를 추가해보자면,
classTestClass(name: String, age: Int){
}
이런 모양이 된다. 이름과 나이를 초기화할 수 있는 기본생성자를 추가해보았다.
만약, 자바였다면 다음과 같았을 것이다.
classTestClass{
String name;
int age;
// 생성자publicTestClass(String n1, int n2){
this.name = n1;
this.age = n2;
}
}
코틀린이 훨씬 간결하다.
2. init
바로 위의 코드처럼 자바에서는 생성자에서 바로 멤버변수들을 초기화 해줄 수 있다.
하지만 코틀린에서는 그러지 못하고 다음과 같은 방법을 사용할 수 있다.
classTestClass(name: String, age: Int){
val name: String = "kim"var age: Int = 0init {
this.age = age
}
}
init은 기본생성자 호출이후 바로 다음에 호출되는 키워드이다.
하지만 우린 굳이 init 안쓰고 받아온 매개변수를 사용할 수 있다.
classTestClass(var name: String, val age: Int){
funintroduce() {
println("Hi! I'm $name and I'm $age years old")
}
}
기본생성자의 매개변수 옆에 var과 val가 슬쩍 생긴것을 볼 수 있다.
얘네들을 붙혀주면 생성자의 매개변수를 클래스 내부에서 사용할 수 있다.
3. 보조생성자 constructor()
클래스 이름 옆에서만 생성자를 만들 수 있는걸까?
생성자를 여러개 만들고 싶을때는 어떻게 하면될까..
우리는 constructor 키워드를 사용할 수 있다.
classTestClass{
var name = ""var age = 0constructor(name: String, age: Int){
this.name = name
this.age = age
}
}
참고로 var name = ""에서 자동으로 String으로 타입추론이 되기에 :String이라고 명시해주지 않아도 된다.
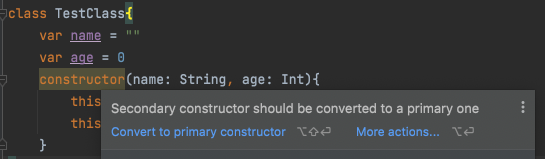
하지만 이렇게 constructor로 생성자를 선언해주면 똑똑한 인텔리제이에서는 이러지 말라고 권유한다.
"Convert to primary constructor"를 누르면
이렇게 다시 정리가 된다.
아무튼 constructor 키워드로 생성자를 여러개 선언해 줄 수 있다.
classTestClass{
var name = ""var age = 0constructor(name: String, age: Int){
this.name = name
this.age = age
}
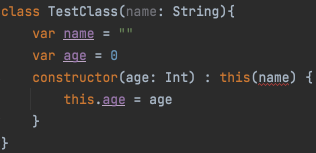
constructor(age: Int){
this.age = age
}
constructor(name: String){
this.name = name
}
}
하지만,
constructor 키워드를 사용할 때 한가지 주의할 것이 있다.
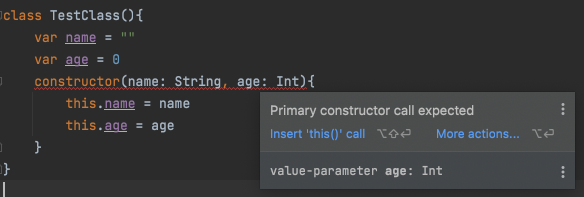
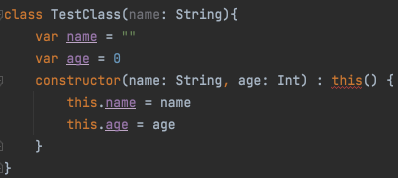
기본 생성자를 선언하고 constructor를 사용하면 다음과 같이 에러가 발생한다.
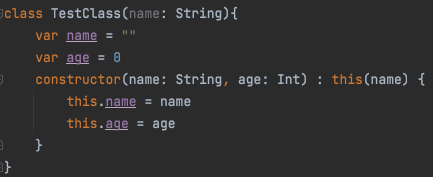
인텔리제이가 하라는 대로 this()를 추가해주면 에러는 사라진다.
왜 이럴까?
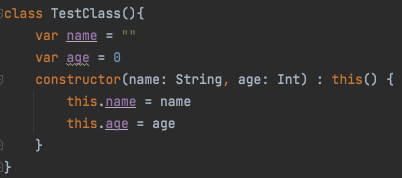
constructor로부터 생성된 생성자는 기본 생성자를 상속받아야 한다.
그렇기 때문에 기본 생성자를 상속받고 난 이후에는 에러가 사라진 것이다.
물론 기본 생성자를 상속 받는 것이니 constructor로 만든 생성자들은 반드시 기본 생성자가 갖고 있는 인자들을 갖고 있어야 한다.
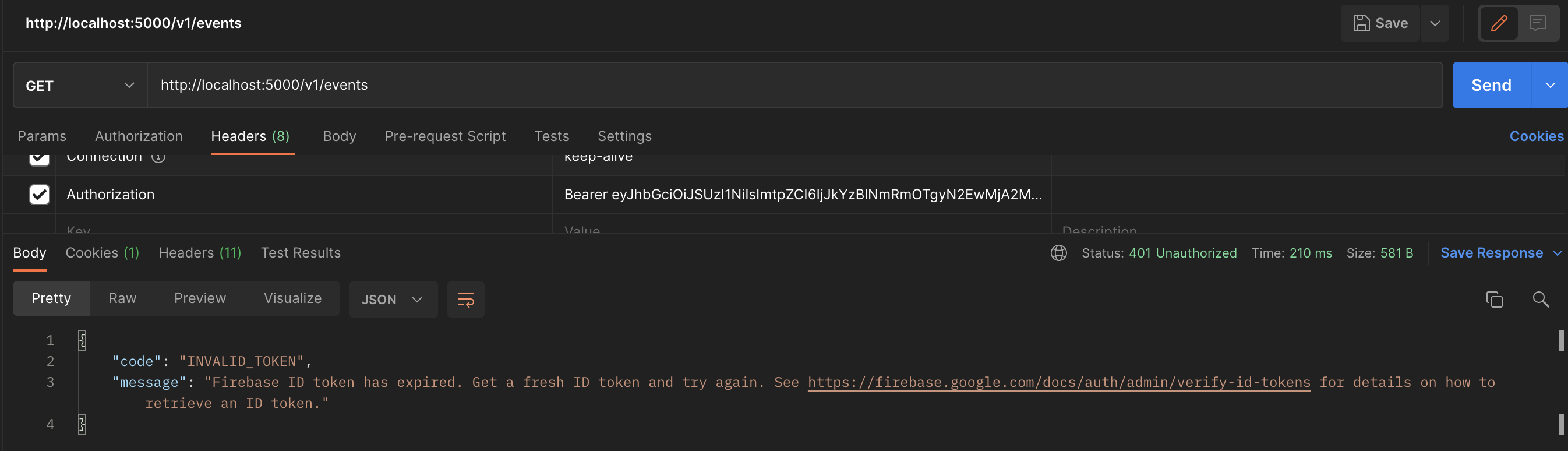
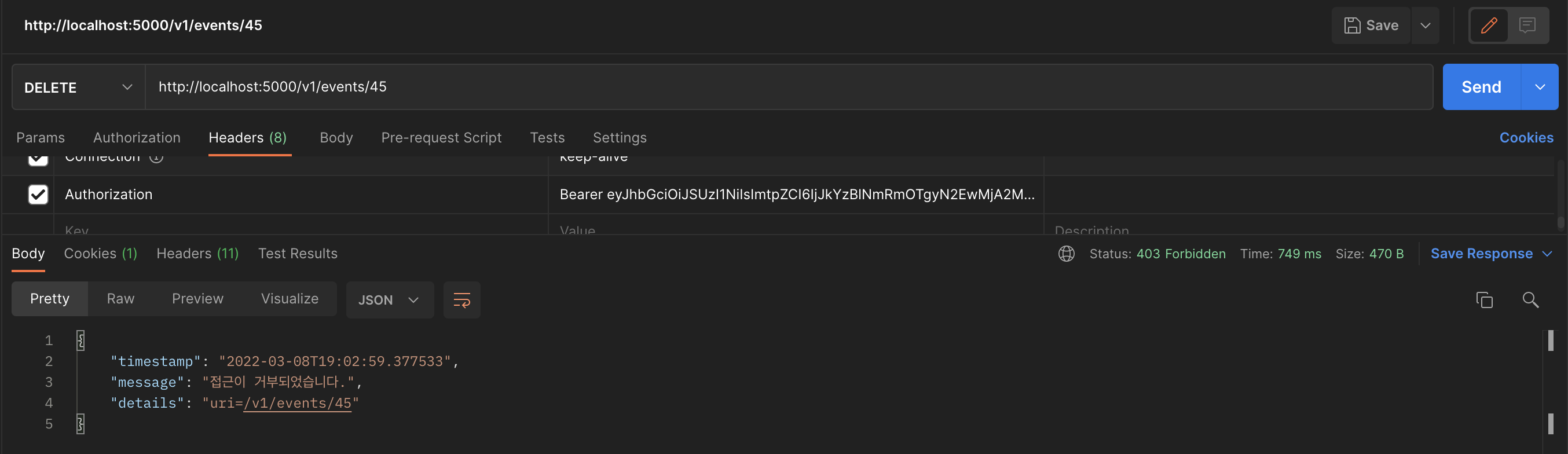
val accessToken = request.getHeader("Authorization").split(" ")[1]
JWT 토큰이 Header에 Authorization: Bearer {jwt token} 형식으로 요청되어지기에 공백을 기준으로 뒷 덩어리를 가져온다.
2. JWT Token 검증하기
val decodedToken: FirebaseToken = FirebaseAuth.getInstance().verifyIdToken(accessToken)
val uid: String = decodedToken.uid
val role: String = decodedToken.claims["group"] as String
Firebase Admin를 통해서 verify한다.
시간이 만료되었거나 잘못된 토큰일 경우 FirebaseAuthException이나 IllegalArgumentException을 뱉는다.