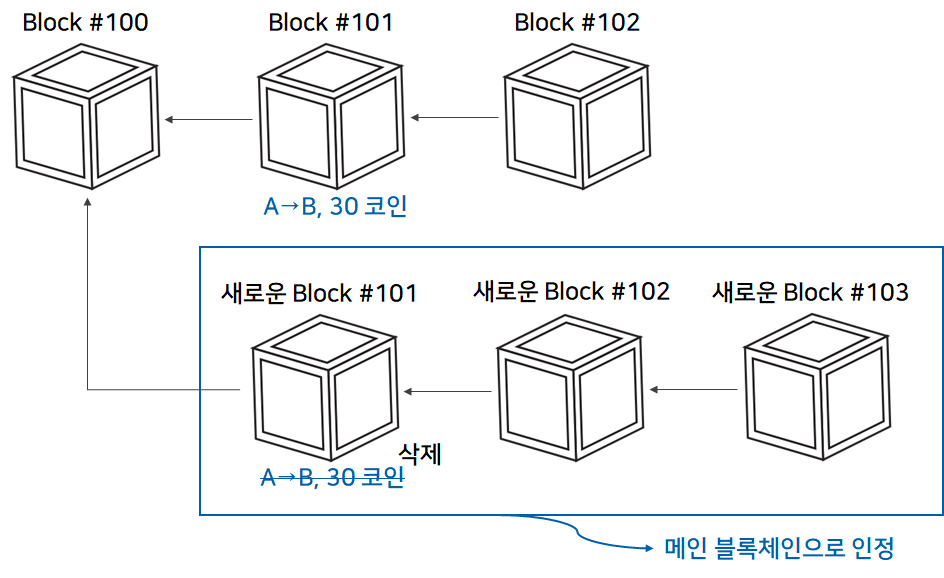
@Override
public void configure(WebSecurity web) throws Exception {
web.ignoring()
.antMatchers("/")
.antMatchers("/ping");
}
@Override
public void configure(HttpSecurity http) throws Exception {
http.csrf().disable()
.authorizeRequests()
.antMatchers("/v1/**").authenticated();
}개발하며 위처럼 파라미터가 다른 두 configure를 재정의해서 사용할 일이 있었다.
HttpSecurity 패턴은 보안처리
WebSecurity 패턴은 보안예외처리 (정적리소스나 health check)
WebSecurity 패턴은 HttpSecurity패턴이 정의되어야 사용할 수 있다.
configure (WebSecurity)
- antMatchers에 파라미터로 넘겨주는 endpoints는 Spring Security Filter Chain을 거치지 않기 때문에 '인증' , '인가' 서비스가 모두 적용되지 않는다.
- 또한 Security Context를 설정하지 않고, Security Features(Secure headers, CSRF protecting 등)가 사용되지 않는다.
- Cross-Site-Scripting(XSS), content-sniffing에 대한 endpoints 보호가 제공되지 않는다.
- 일반적으로 로그인 페이지, public 페이지 등 인증, 인가 서비스가 필요하지 않은 endpoint에 사용한다.
configure (HttpSecurity)
- antMatchers에 있는 endpoint에 대한 '인증'을 무시한다.
- Security Filter Chain에서 요청에 접근할 수 있기 때문에(요청이 security filter chain 거침) 인증, 인가 서비스와 Secure headers, CSRF protection 등 같은 Security Features 또한 사용된다.
- 취약점에 대한 보안이 필요할 경우 HttpSecurity 설정을 사용해야 한다.
참고:
https://velog.io/@gkdud583/HttpSecurity-WebSecurity%EC%9D%98-%EC%B0%A8%EC%9D%B4
[Spring] HttpSecurity, WebSecurity의 차이
HttpSecurity와 WebSecurity의 차이점에 대해 찾아본 내용을 정리한 글입니다.antMatchers에 파라미터로 넘겨주는 endpoints는 Spring Security Filter Chain을 거치지 않기 때문에 '인증' , '인가' 서비스가 모두 적용
velog.io
http://daplus.net/java-httpsecurity-websecurity-%EB%B0%8F-authenticationmanagerbuilder/
[java] HttpSecurity, WebSecurity 및 AuthenticationManagerBuilder - 리뷰나라
사람이 대체 할 때 설명 할 수있는 configure(HttpSecurity), configure(WebSecurity)그리고 configure(AuthenticationManagerBuilder)? 답변 configure (AuthenticationManagerBuilder) 는 AuthenticationProviders를 쉽게 추가 할 수 있도록
daplus.net
https://dev-elop.tistory.com/entry/Spring-Security-HttpSecurity-WebSecurity-%EC%B0%A8%EC%9D%B4
Spring Security HttpSecurity, WebSecurity 차이?
스프링 시큐리티 설정 중에 //패턴을 이용해서 접근막음 @Override protected void configure(HttpSecurity http) throws Exception {} //위에서 적용한 패턴의 제외한 접근 - 정적리소스, HTML 파일 허용처리 @Ov..
dev-elop.tistory.com
'Spring' 카테고리의 다른 글
| [Spring] Spring Security에서 Firebase JWT사용하기 (0) | 2022.03.08 |
|---|---|
| [Spring] JWT Refresh Token을 사용한 로그인과 고찰 (7) | 2021.08.20 |
| [Spring] JWT를 사용한 로그인 구현 1 (2) | 2021.08.02 |
| [Spring] H2 데이터베이스 사용하기 (0) | 2021.08.01 |
| [Spring] 카카오 아이디로 로그인하기 - 2 (0) | 2021.07.29 |