혼자 개발할때는 사용하지 않고 그냥 이런게 있구나 정도로 넘겼던 도커.
이제 막 배우기 시작하는 입장으로서 한번 개념만 정리해보자.
1. 부두 노동자

어학사전에 docker를 검색하면 부두(항만) 노동자라고 나온다.
해외에서
화물 컨테이너가
배를 타고 부두에 도착하면
노동자들이
화물 컨테이너를 받아준다.
이를 도커로 바꿔보면
해외(도커 레지스트리)에서
화물 컨테이너(도커 이미지)가
부두(나의 PC)에 도착하면
노동자(도커)들이
화물 컨테이너를 받아준다(도커 이미지를 도커 컨테이너로 만들어 실행시킨다)
이 비유가 맞다고 확신은 못하지만 내 생각엔 맞는 것 같다.(아니라면 알려주세요ㅠㅠ)

2. 컨테이너 기반 가상화 플랫폼?
혼자 개발할때는 나의 PC에 필요한 소프트웨어들을 미리 설치해두고 개발한다. 내가 작성한 코드들은 미리 설치해둔 환경에 의존하며 실행된다. 여기까진 좋은데 내가 만든 것을 배포하려면 어떻게 해야할까? 사용자들도 나의 PC와 같은 환경이 미리 준비돼 있어야 내가 만든 SW가 정상적으로 동작할텐데 말이다. 이때 도커를 사용한다.
도커는 애플리케이션을 어떤 환경에서도 자유롭게 사용할 수 있게 해준다.
도커의 역할을 한마디로 요약해보면
"내가 만든 애플리케이션과
애플리케이션에 요구되는 환경을
몽땅 압축해서 배포하기"
and
"남이 만든 애플리케이션을
애플리케이션에 요구되는 환경과 함께
한번에 받아와서 실행하기"
정도이려나?
(피드백 달게 받습니다..)
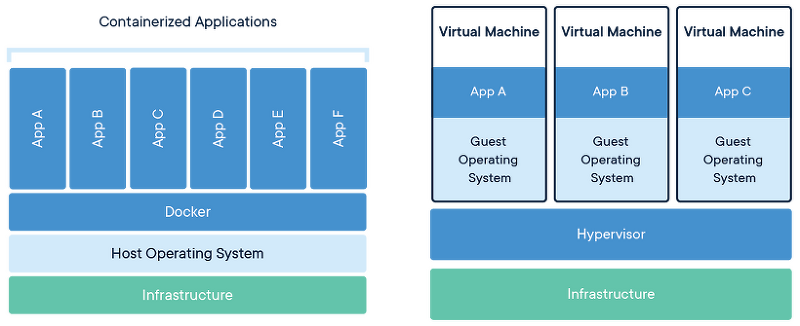
VM과 비슷한 개념이긴 하나 VM은 OS위에 다른 OS를 생으로 다시 올린다. 각 VM은 하나의 서버를 여러 서버로 전환하는 물리적인 하드웨어의 추상화라고 하는데 이는 매우매우 무겁다.
도커는 여러 종류의 컨테이너가 동일한 시스템에서 실행되고 호스트의 OS 커널을 다른 컨테이너와 공유할 수 있기에 VM보다 부담이 적다. 즉, 실제로(HW적으로) 내 PC에서 공간을 나누진 않았지만 각각의 독립된 공간을 가진것 처럼 동작하도록 하는 기술이다.
3. 이미지, 컨테이너, 레지스트리
나의 애플리케이션, 혹은 누군가 만들어 놓은 애플리케이션의 실행에 필요한 모든 것들(라이브러리, 미들웨어, OS, 네트워크 설정 등)을 모아서 도커 이미지라는 것으로 만든다.
이 이미지들을 클라우드상에 모아놓은 곳을 레지스트리라고 한다.
대표적인 레지스트리로 도커허브가 있다.
내가 만든 이미지나 남이 만들어 놓은 이미지들을 올리고 내려받을 수 있다.
이 이미지들을 내려받아서 실행시킨 것을 컨테이너라고 한다.
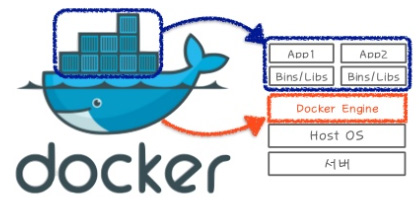
이 고래가 도커엔진이고 위에 네모난 것들이 이미지를 내려받아 생성한 컨테이너다.
즉 도커 엔진 위에서 여러 컨테이너들이 실행중인 모습을 보여준다.
이미지를 실행한 상태인 컨테이너는 애플리케이션을 패키징/캡슐화하여 격리된 공간에서 프로세스를 동작시킨다.
일단은 내 로컬 PC 어딘가에서 프로세스가 실행되는 것이긴 한데 이 공간은 내가 접근할 수 없는 격리된 공간이다.
컨테이너의 특징을 정리하자면
- 가상머신과 비교하여 컨테이너의 생성이 쉽고 효율적이다.
- 컨테이너 이미지를 통한 배포와 롤백이 간단하다.
- 언어나 프레임워크에 상관없이 애플리케이션을 동일한 방식으로 관리한다.
- 개발, 테스팅, 운영 환경은 물론 로컬 PC와 클라우드까지 동일한 환경을 구축한다.
- 특정 클라우드 벤더에 종속적이지 않다.
4. 레이어
도커 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기에 용량이 보통 수백MB다.
따라서 기존 이미지에서 살짝 무언가가 추가된 이미지를 다시 받는다고
이미지 전체를 다시 받으면 용량적으로 비효율적이다.
따라서 이미지는 레이어로 구성되어있다.
이미지1이 A+B+C의 레이어(구성 요소)로 이루어져있는데
C를 수정한 A+B+C*의 이미지를 받아야 한다면 C레이어만 C*로 수정된다.
위 그림에서 MySQL의 버전이 변경된 새로운 이미지를 내려 받는 경우를 생각해보면 될 것이다.
이미지를 내려받을 때 다음과 같은 로그가 나온다.
$ docker pull mysql
Using default tag: latest
latest: Pulling from library/mysql
69692152171a: Extracting [=======> ] 4.129MB/27.15MB
1651b0be3df3: Download complete
951da7386bc8: Download complete
0f86c95aa242: Download complete
37ba2d8bd4fe: Download complete
6d278bb05e94: Download complete
497efbd93a3e: Download complete
f7fddf10c2c2: Download complete
16415d159dfb: Downloading [> ] 2.157MB/115.8MB
0e530ffc6b73: Download complete
b0a4a1a77178: Waiting
cd90f92aa9ef: Waiting
69692152171a와 같은 한 줄 한 줄이 모두 레이어이다.
이런 레이어가 한 겹 한 겹 쌓이고 하나의 이미지로 만들어진다.
이후 이 이미지를 docker run으로 실행하면 도커가 관리하는 파일 시스템 영역에 이미지를 복사한다.
복사 후 이미지 레이어 최상단에 컨테이너 레이어를 추가한다. 이로써 이미지는 컨테이너가 된다.
그리고 사용자에겐 Union File System을 사용하여 레이어가 스택 구조로 쌓인 이미지를 하나의 파일 시스템처럼 보이게 한다.
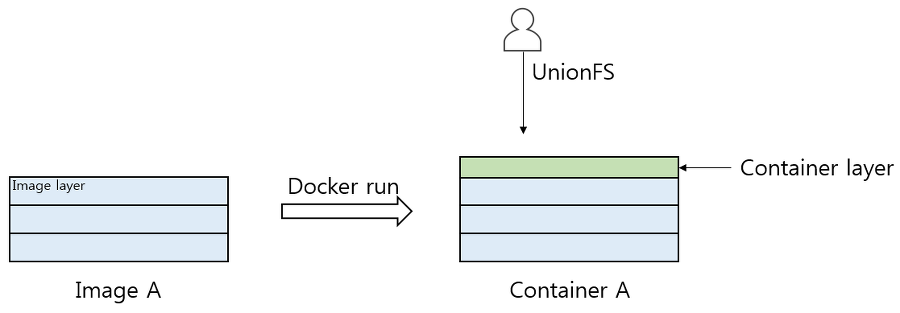
컨테이너 레이어는 변경 가능하고,
이미지 레이어는 변경 불가능하다.
컨테이너 레이어는 컨테이너 종료 시 소멸되고,
이미지 레이어는 삭제되지 않는다.
레이어를 사용하면 위에 말했 듯 애플리케이션의 일부를 변경할 경우 이미지 전체를 다시 다운받지 않고
변경된 부분의 레이어만 교체해 주면 된다.
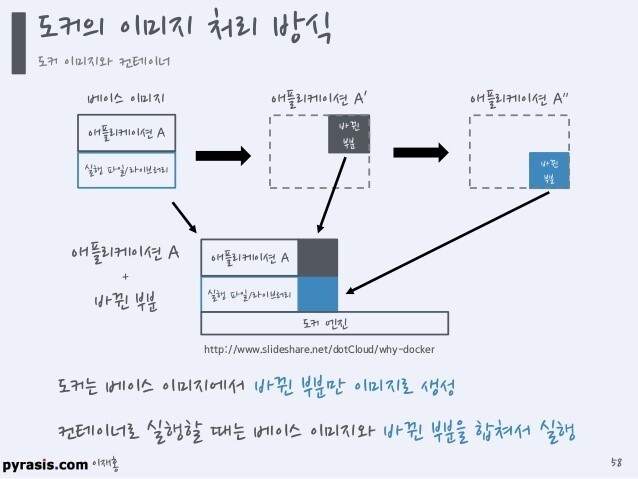
5. 정리
그림으로 도커의 전반적인 동작을 정리해보자
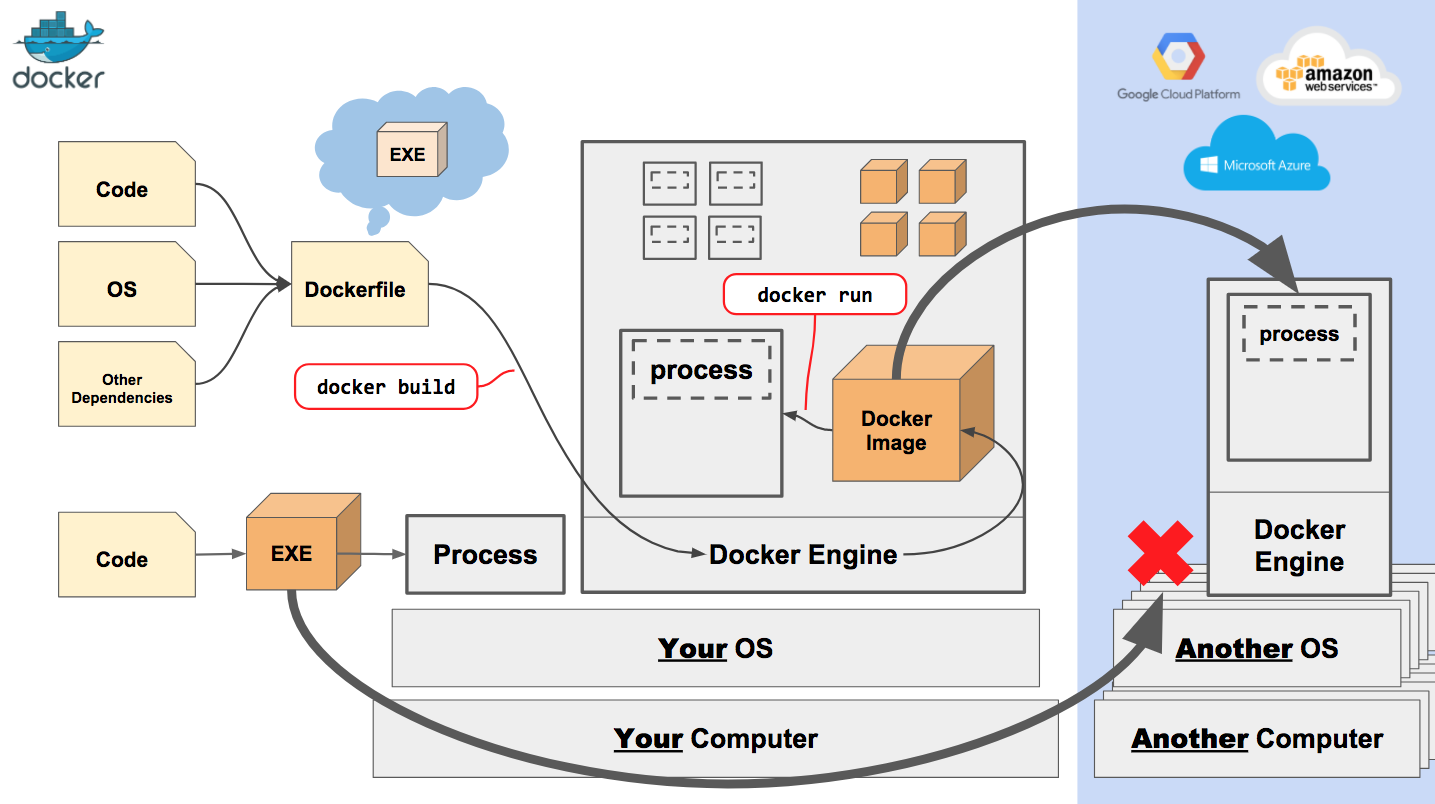
왼쪽에 (Code, OS, Other Dependencies)가 Dockerfile로 합쳐지고 이를 build하여 도커 이미지를 생성함을 볼 수 있다.
이렇게 생성된 이미지는 내 PC에 있는 도커엔진에서 실행되어 컨테이너 상태가 된다.
또 왼쪽에 EXE파일로 실행한 프로세스를 확인할 수 있는데 이건 내 PC위에서 실행되는 일반적인(도커가 아닌) 프로세스를 표현한 것 같다.
자 이제 이렇게 내 PC에서 실행되고 있는 두 프로세스(도커 컨테이너와 일반 프로세스)를 그림 우측처럼 다른 환경으로 옮기면 어찌될까?
도커를 통한 공유(배포)는 애플리케이션 실행을 위한 환경이 모두 준비된 이미지를 배포하기에 다른 환경이라도 이를 받아줄 수 있는 도커 엔진만 있다면 정상적으로 동작한다.
단, 일반적인 프로세스라고 표현한 저 애플리케이션은 내 PC와 다른 환경이기에 동작하지 않을 수도 있다.
참고:
https://futurecreator.github.io/2018/11/16/docker-container-basics/
도커 Docker 기초 확실히 다지기
이전 개발자를 위한 인프라 기초 총정리 포스트에서 컨테이너와 도커에 대해 간단히 살펴봤습니다. 이해하기 어려운 개념은 아니지만 막상 뭔가를 하려면 막막할 수 있는데요, 이번 포스트에서
futurecreator.github.io
https://dev-youngjun.tistory.com/2
도커란 무엇일까요?
Docker Preference Ubuntu 16.04 Docker CE Docker Hub 계정 목차 1. What Is Docker? 2. Docker 주요개념 2-1. 이미지(Image) 2-2. 컨테이너(Container) 1. What Is Docker? 컨테이너 기반의 오픈소스 가상..
dev-youngjun.tistory.com
[Docker]Docker는 무엇인가? 도커의 기초와 이미지 설치하고 사용(1)
요즘 도커가 대세다... 라고 말하기도 애매하게 도커가 대세가 된지는 좀 된거 같다. 도커는 여러가지의 장점과 여러가지의 단점을 가지고 있어서 무조건 좋다고 말하기는 애매한 것 같다. 일단
kamang-it.tistory.com
도커 컨테이너(Container)와 이미지(Image)란?
도커(Docker)는 Immutable Infrastructure Paradigm 이라는 개념을 기반으로 하기 때문에, 서비스 환경(서비스 인프라) 부분을 이미지화(실행파일화)하여 배포한 뒤 가급적 변경하지 않고 사용한다고 이전
hoon93.tistory.com
https://khj93.tistory.com/entry/Docker-Docker-%EA%B0%9C%EB%85%90
[Docker] Docker의 개념 및 핵심 설명
Docker란 Go언어로 작성된 리눅스 컨테이너 기반으로하는 오픈소스 가상화 플랫폼이다. 현재 Docker 0.9버전 부터는 직접 개발한 libcontainer 컨테이너를 사용하고 있다. 가상화를 사용하는 이유
khj93.tistory.com
http://itnovice1.blogspot.com/2019/08/blog-post_83.html
[운영체제] 커널이란?
[운영체제] 커널이란? 일반적인 커널의 형태 맨 위의 Applications가 응용 프로그램이다. 그 밑에 존재하는 것이 커널 커널 밑에 각종 하드웨어(CPU, Memory, Devices)들이 있는 것을 알 수 있다. ...
itnovice1.blogspot.com
https://eqfwcev123.github.io/2020/01/30/%EB%8F%84%EC%BB%A4/docker-image-layer/
docker 이미지 레이어(Docker Image Layer)
Docker Image Layer의 구조 Docker 의 이미지를 이용해서 docker run 을 하면 Docker 는 도커가 관리하는 파일 시스템 영역에 이미지를 복사한다. 복사후 docker는 이미지의 최상단에 컨테이너 레이어 라고 불
eqfwcev123.github.io
'DevOps' 카테고리의 다른 글
| [docker] 도커 초기화하기 (0) | 2023.04.20 |
|---|---|
| [DevOps] Github Actions로 AWS Elastic Beanstalk에 Nodejs 배포하기 (0) | 2021.12.01 |
| [DevOps] CI/CD 파이프라인이란 (0) | 2021.11.17 |